
“はたらく”を支えるリコーの大規模言語モデル(LLM)
リコーは、お客様の用途や環境に個別最適な企業独自の生成AIを、プライベート環境かつ低コスト・短納期で提供することを目指し、複雑な図表を多用する日本企業に特有の書式に対応した大規模言語モデル(LLM)を開発しています。
大規模言語モデル(LLM)とは
企業の生産性や競争力を強化するためのツールとして、「生成AI」が注目されています。イラストや画像の生成AI、音声の生成AI、動画の生成AIなどさまざまな種類が登場していますが、その中でも近年とくに関心を寄せられているのが「LLM」です。
LLM(Large Language Model)は、日本語では「大規模言語モデル」とも呼ばれます。ディープラーニング(深層学習)によって膨大なテキストデータを学習し言語処理を行うAIモデルを指し、文章生成をはじめ、さまざまな用途に活用されています。
また、LMM(Large Multimodal Model)は、テキストに加えて画像や動画などの複数のデータ形式を扱えるAIモデルです。日本語では「大規模マルチモーダルモデル」と呼ばれています。LLMが主にテキストの理解・生成に特化しているのに対し、LMMはテキスト・画像・音声など複数の形式を統合的に理解・生成できる点が特徴です。

お客様のニーズとリコーのLLMが解決すること
リコーは、お客様が業務に安心して活用できるLLMの開発に取り組んでいます。
お客様のニーズ・課題

労働力の減少に対応した効率的な働き方や、ベテラン社員の退職に伴う技能伝承が必要
外国人労働者の増加に伴う社内文書の多言語化への対応が求められている

知の結晶である社内文書の活用が急務だが、企業内にはデータ形式や項目名が定まっていない非構造化データが膨大に存在し、効果的な活用ができていない
例:スキャンされた紙の書類、PDFファイル、メールなど

個人情報、社外秘情報などのセキュリティを確保した環境で利用したい
リコーのLLMが解決すること

日本企業特有の、複雑な図表を含む文書からでもQ&A方式で知識を引き出せる

精度を維持したままコストを抑えることができる

セキュリティを担保できるオンプレミス環境で個別カスタマイズ(プライベート化)が可能
提供サービス
RICOHオンプレLLMスターターキット
「高セキュリティ・低コスト・高性能・活用の自由度」を兼ね備えた高セキュリティなオンプレLLMの導入から運用までをご支援するローカルLLMパッケージ

-
※「日経優秀製品・サービス賞」は毎年1回、日本経済新聞社が独自に選定した候補の中から、特に優れた新製品・新サービスを審査委員会が選出し、表彰するものです。同賞は、1982年に「日経・年間優秀製品賞」として始まり、1987年(第6回)から現在の名称に変更し、今回で44回目です。

リコーのLLMの特徴
リコーでは、業務現場で安心して活用できる生成AIを実現するために、独自の大規模言語モデル(LLM)と大規模マルチモーダルモデル(LMM)、さらにセーフティ技術を組み合わせたラインアップを開発しています。
特徴
- 最新のOSS(オープンソース・ソフトウェア)のLLMを日本語に最適化し、お客様の業務にフィットするようチューニング
- 公開データに加えて、研究機関連携や独自開発によって蓄積した豊富な学習データを用いることで、図面を含む設計図書や図表を多く掲載したIR文書をはじめとする多様なビジネス文書の読み取りに対応
- オンプレミス環境を想定し、小型化と高性能を両立。ラックマウント型サーバーから小型PCサーバーまで搭載が可能なLLM/LMMラインアップを開発
モデル
リコーのLLM/LMMの中核となるモデルをご紹介します。

リコーのLLM/LMMモデルラインアップ(2026年6月5日時点)
大規模言語モデル(LLM:Large Language Model)— 日本語に強い高性能モデル
リコーLLM_70B(Built with Llama)は、リコー独自の学習データやノウハウを活用したモデルマージによる性能向上と多段推論能力の付与により、複雑なタスクにおいても高い性能を発揮します。
- 多数の条件や制約を踏まえた回答
- 長文や複雑な文書の理解と情報の統合
- ステップに分解した計画立案
元々は金融業特有の専門用語や知識を強化した金融業務特化モデルとして開発しましたが、他の用途においてもその高い性能を活用可能です。
リコーLLM_27Bは、コンパクトながら高性能なモデルで、低コストで導入可能であることから幅広い用途で利用可能です。高い初期応答性と執筆能力を兼ね備え、ビジネス用途に好適なモデルになっています。
大規模マルチモーダルモデル(LMM:Large Multimodal Model)— 多様なデータ形式を理解
リコーLMM_70B(Built with Llama)は、GENIAC基盤モデル開発第2期で開発したモデルです。テキストだけでなく文書中の図表にも対応した処理ができるAIで、業務で頻出する以下のような複合的なタスクで高い性能を発揮します。
- 画像や図表の読み取り
- スクリーンショットの要約
- 図を含む質問への回答
- テキストと画像を組み合わせた高度な指示への対応
Llama-3.1 SwallowをベースのLLMに、画像エンコーダにはQwen2-VLのVision Encoderを統合したモデルです。日本語図表に特化した合成データ約600万枚で学習しており、文書画像中の図表を高精度に読み取る能力を実現しています。
リコーLMM_27Bは、GENIAC基盤モデル開発第3期で開発したLMM_32Bの後継モデルです。多段推論(リーズニング)性能、つまりLLMが単に情報を検索したりテキストを生成したりするだけでなく、複数のステップからなる論理的な思考プロセスを経て結論を導き出す能力を強化したLMMで、企業内ドキュメントの高度な読解や意思決定支援が可能になります。
- 文書の構造理解
- 因果関係の把握
- 重要情報抽出
- 複数ステップの論理的思考(multi-step reasoning)
リコーLMM_9Bは、GENIAC基盤モデル開発第3期で開発・公開したLMM_8Bの後継モデルです。LMM_27Bと同じ設計思想のもと、より広いハードウェア環境への導入を実現したコンパクトモデルで、汎用GPUサーバー1台構成でも、企業内ドキュメントの読解や意思決定支援に活用できます。
セーフガードモデル — 安全に使える生成AIを提供
生成AI利用時の安全性を確保するため、LLM専用のセーフガード(ガードレール)モデル(Built with Llama)を開発しています。「入力」「出力」の安全性チェックに対応します。
- 不適切・有害な入出力の検知
- 暴力/犯罪/差別/プライバシー侵害などのカテゴリー判別
ガードレールLLMの重要性が高まる一方で、日本のビジネスの現場で実用的に利用できるモデルは少ない状況があります。リコーは、セーフガードモデルの重要性を社会に提起するとともに、生成AIの安全な利活用の推進に貢献することを目的として、本モデルを無償公開しています。
リコーのLLM/LMMラインアップの特徴比較
| モデル | リコーLLM_70B | リコーLLM_27B | リコーLMM_70B | リコーLMM_27B | リコーLMM_9B | リコーLMM_8B |
|---|---|---|---|---|---|---|
| 性能 | GPT-5並み | GPT-5-nano並み | Gemini 3 Pro Preview並み | |||
| ベース | Llama3.3 | Gemma 3 | Qwen2-VL + Llama 3.1 | Qwen3.6 | Qwen3.5 | Qwen3-VL |
| 特徴 |
|
|
|
|
|
|
| 提供方法 | RICOHオンプレLLMスターターキット |
|
Hugging Faceで無償公開 | RICOHオンプレLLMスターターキット(予定) | RICOHオンプレLLMスターターキット(予定) | Hugging Faceで無償公開 |
-
※性能の表記は、Japanese MT-Bench、 ELYZA-tasks-100 およびJDocQA等に基づく当社評価による性能水準の比較であり、各社の公式モデルの利用や同一性を示すものではありません。
-
※Hugging Faceは、AIモデルやデータセットを公開・共有するためのプラットフォームです。研究用途から商用検証まで幅広く利用されています。
データ
リコーは技術倫理、データガバナンスポリシーを遵守して開発を行っており、お客様の情報を学習に一切使っていません。
LLMの学習に使うデータは、模擬データ、合成・拡張データ、これまでの研究開発で蓄積した内部データであり、これらを使って学習したリコーのモデルも安心して使っていただけます。
LLMの性能向上にはデータの量だけでなく、データの品質が重要です。リコーは、国立研究開発法人理化学研究所 革新知能統合研究センター 言語情報アクセス技術チーム(理研 AIP)が主催する日本語インストラクションデータ作成プロジェクトに参画するとともに、リコー独自開発のインストラクションデータを開発するなど、データ品質の向上にも取り組んでいます。
また、AIの性能評価をするには、客観的に比較できるベンチマークが不可欠です。リコーがGENIAC基盤モデル開発第3期で開発した、ドキュメント理解におけるAIの推論(リーズニング)性能を評価するベンチマークツール「JDocQA Reasoning Benchmark」は、図表を含む日本語業務文書に対して、単なる情報抽出にとどまらず、計算・比較・傾向分析など複数段階の推論能力を評価できる点が特徴です。リコーは本ベンチマークを無償公開することで、生成AIの実用化に向けた技術基盤の高度化に寄与します。
開発成果
リコーは2022年から大規模言語モデル(LLM)の研究・開発にいち早く着手し、2023年3月にはリコー独自のLLMを発表。経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」基盤モデル開発に、2024年10月の第2期、2025年7月の第3期と連続で採択されています。
進化のスピードを増すAI技術を“はたらく”現場での価値に変えるため、モデルそのものの高度化と並行して、設計から運用までを見据えた「AIの生産技術」を強化していきます。
※記載内容は発表当時のものです。
株式会社リコーは、図表や複雑なレイアウトを含む日本語ドキュメントにおける読解性能を向上させる「ドキュメント読解強化ワークフロー」(特許出願済み)を開発しました。本技術は、今夏から生成AIアプリ開発プラットフォーム「Dify(ディフィ)」のテンプレートとして「RICOH オンプレLLMスターターキット」への搭載を予定しています。これにより、企業におけるドキュメント活用の高度化と業務革新に寄与します。
1. 背景
生成AIの急速な普及に伴い、日本企業では企業内ドキュメントの高度な活用を目的としたAI需要が高まっています。企業内には、請求書や経営資料、マニュアルなど多様なドキュメントが蓄積されていますが、これらには図表や画像も含まれるため、従来のテキスト検索では十分に活用できないという課題があります。また、セキュリティやプライバシー、ガバナンスの観点から、オンプレミス環境や自社データセンターでAIを活用したいというニーズが高まっています。リコーは、こうした企業ニーズに応えるため、「RICOH オンプレLLMスターターキット」を開発し、順次、機能強化を進めています。
さらにリコーは、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」*1基盤モデル開発 第2期・第3期に参画し、日本企業がオンプレミス環境で活用可能なマルチモーダル大規模言語モデル(LMM)および性能評価のためのベンチマークの開発に取り組んできました。
また、2026年5月に、中国のアリババクラウドが開発・提供する大規模言語モデルファミリーの「Qwen3.6-27B」をベースに、日本語のリーズニング性能を大幅に向上させた「Qwen3.6-Ricoh-27B-20260522」を開発するなど、日本企業の業務で活用できるドキュメント読解に強みを持つAI開発を続けています。今回、これらの知見を活かし、マルチモーダルLLMと組み合わせることで読解性能を向上させるワークフローを開発しました。
2. 開発の成果
今回開発したワークフローは、図表を含むビジネスドキュメント理解において、テキスト、図、表などの情報を効率的に抽出するドキュメント解析処理を採用しています。これにより、本文と図表の関係性を踏まえた回答生成が可能となり、従来の方法に比べて、ビジネスドキュメントの読解精度が大幅に向上します。
また、同一LLMから生成される複数の回答候補を統合する「Self-MoA(Self Mixture-of-Agents)」を採用しています。この技術により、複数LLMを組み合わせる従来の「MoA(Mixture-of-Agents)」方式に比べ、GPUリソースを効率的に活用しながら、回答品質の向上を実現しました。
ドキュメント解析処理とSelf-MoAを組み合わせることで、図表を含む日本語ドキュメント理解におけるリーズニング性能を高めます。
評価には、リコーが独自に構築したベンチマーク「JDocQA Reasoning Benchmark」を用いました。本ベンチマークは、図表を含む日本語業務文書に対して、単なる情報抽出にとどまらず、計算・比較・傾向分析など複数段階の推論能力を評価できる点が特徴です。
2026年3月30日のニュースリリースで開発完了を発表したLMM「Qwen3-VL-Ricoh-32B-20260227」の4bit量子化モデルに本ワークフローを適用した結果、ベースライン方式で0.791から0.830へ、+3.9pt向上しました。
また、2026年6月5日のニュースリリースで発表したLMM「Qwen3.6-Ricoh-27B-20260522」の8bit量子化モデルに適用した場合も、スコアは0.875から0.904へ、+2.9pt向上し、本評価条件において、Gemini 3.5 Flashの0.889を上回る結果となりました。
このように、異なるLMMに本ワークフローを適用した場合でも、いずれもベースライン方式を上回る結果となりました。これにより、LLM自体を追加学習することなく、利用するLLMをプラグ&プレイで入れ替えた場合でも、本ワークフローにより、図表を含む日本語ドキュメント理解におけるリーズニング性能を向上できることを確認しました。
図表読解のベンチマーク評価結果
| モデル | ベースライン方式 | 提案ワークフロー |
|---|---|---|
| Qwen3-VL-Ricoh-32B-20260227-W4A16 | 0.791 | 0.830(+3.9pt) |
| Qwen3.6-Ricoh-27B-20260522-AWQ-W8A16 | 0.875 | 0.904(+2.9pt) |
| (参考)Gemini 2.5 Flash | 0.771 | |
| (参考)Gemini 2.5 Pro | 0.824 | |
| (参考)Gemini 3 Flash Preview | 0.860 | |
| (参考)Gemini 3.1 Pro Preview | 0.880 | |
| (参考)Gemini 3.5 Flash | 0.889 |
評価条件について
- 評価はOpenAI APIのgpt-4.1-2025-04-14によるLLM-as-a-Judgeで実施
- 各評価は、推論および採点を5回実施し、その平均値をスコアとして記載
- 「JDocQA Reasoning Benchmark」全1,362件のうち、1ページ内の図表やテキストを読み取って回答する単ページ問題1,208件を抽出して評価
3. 技術の特徴
本ワークフローは、図表や複雑なレイアウトを含むドキュメントに対して、まずドキュメント解析処理を行い、テキスト・図・表などの情報を抽出・整理します。そのうえで、整理した情報をLLMに入力し、Self-MoAにより複数の回答候補を生成・統合することで、最終回答を作成します。
図1は、本ワークフローの全体像を示しています。元の文書画像に加えて、OCRで読み取った文字情報や、見出し・本文・図・表などの領域情報を読み取り補助情報としてLLMに渡し、Self-MoAによって複数の回答候補を比較・統合します。これにより、本文と図表の関係を踏まえた回答生成と、リーズニングの精度向上を図ります。
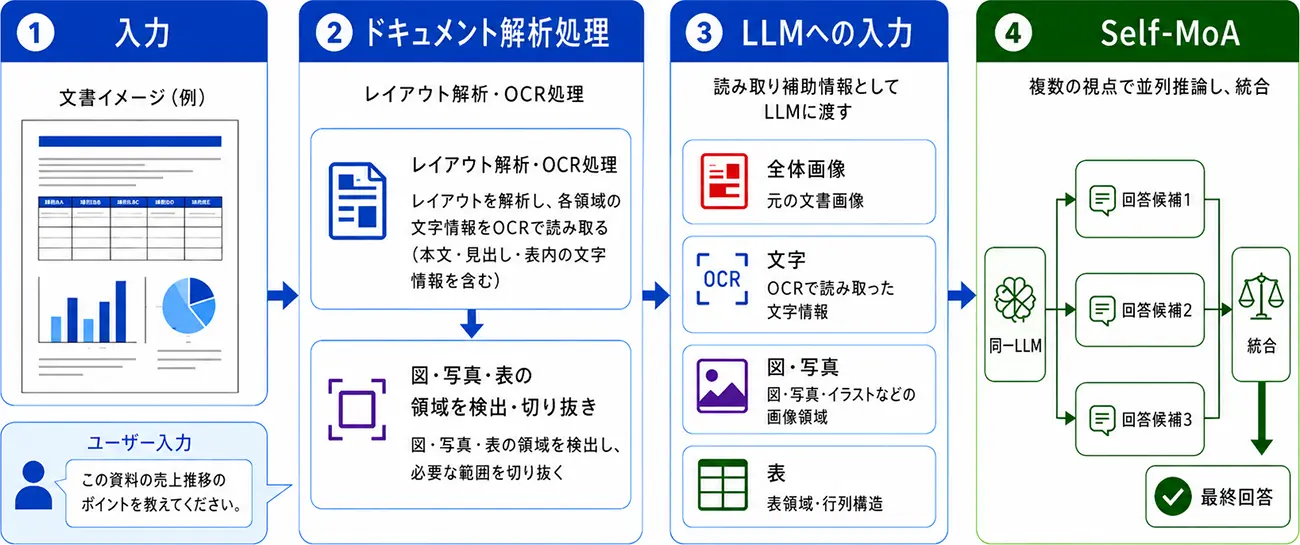
図1. ドキュメント読解強化ワークフローの全体像
(1) ドキュメント解析処理により、本文と図表の関係を踏まえた回答生成を実現
ドキュメント解析処理では、図表や複雑なレイアウトを含むドキュメントから、テキスト・図・表などの情報を抽出し、回答生成に活用します。LLMは、文書全体の見た目だけでなく、見出し・本文・表内の文字、図表の構造などを参照できるため、本文と図表の関係を踏まえた回答生成が可能になります。
図2は、ドキュメント解析処理により、見出し、本文、図、表などの領域を抽出する流れを示しています。図3は、LLMに渡す読み取り補助情報の構成を示しています。本ワークフローでは、元の文書画像である全体画像に加えて、OCRで読み取った文字情報、図・写真などの画像領域、表領域を追加し、文書全体の見た目と構造情報をあわせて活用します。
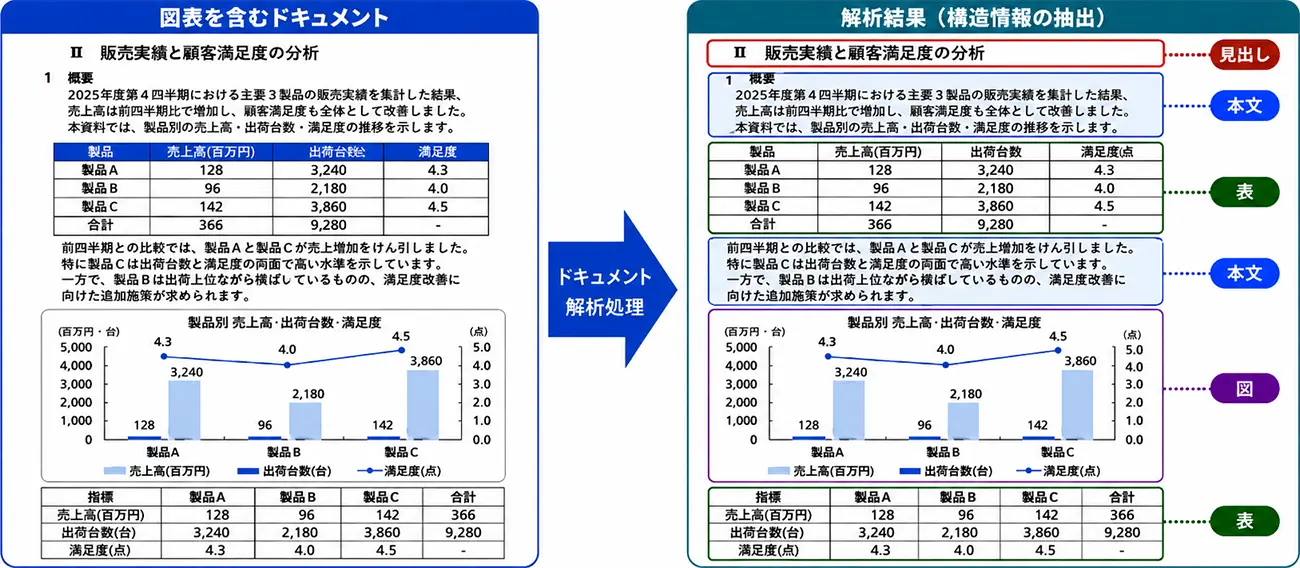
図2. ドキュメント解析処理の概要

図3. LLMに渡す情報
(2) Self-MoAにより、回答品質とGPUリソース効率を両立
Self-MoAでは、同じ入力情報を用いながら、推論時の条件を変えて複数の回答候補を生成し、それらを比較・統合して最終回答を作成します。これにより、1回の推論では見落としやすい観点や中間ステップを取り込みやすくなり、読み取った情報をもとにしたリーズニングの精度向上を図ります。
図4は、複数のLLMを組み合わせる一般的なMoA方式と、同一LLMから複数回答を生成して統合するSelf-MoA方式の違いを示しています。Self-MoA方式では、1種類のLLMで複数の回答候補を生成・統合するため、複数のLLMを組み合わせる方式と比べてGPUメモリ使用量を抑えながら、回答品質を高めることができます。
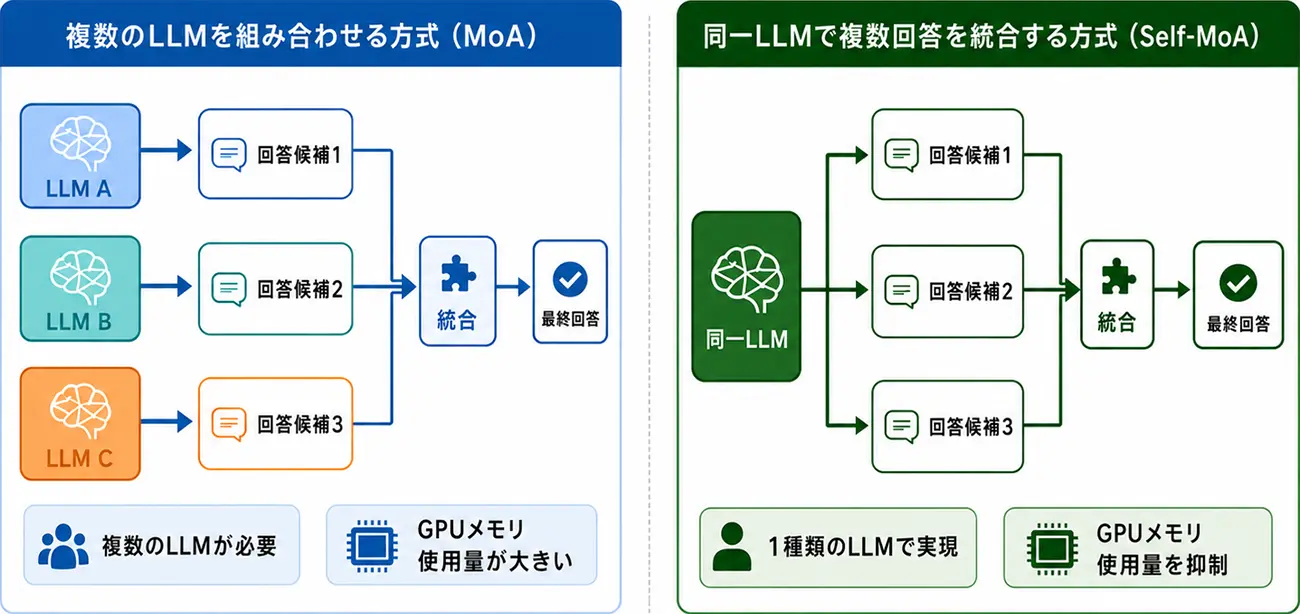
図4. MoA方式とSelf-MoA方式の比較
(3) LLMをプラグ&プレイで入れ替え可能
本ワークフローは、LLM自体を追加学習することなく、利用するLLMをプラグ&プレイで入れ替えられる構成です。ドキュメント解析処理やSelf-MoAは、LLMに入力する情報の整理方法と、回答候補の生成・統合方法を工夫するものです。そのため、モデルそのものを再学習せずに、利用するLLMを入れ替えた場合でも、図表を含むドキュメントの読解性能向上を図ることが可能です。
ニュースリリース
※記載内容は発表当時のものです。
株式会社リコーは、中国のアリババクラウドが開発・提供する大規模言語モデルファミリーの「Qwen3.6-27B」をベースに、日本語でのリーズニング性能を大幅に向上させたマルチモーダル大規模言語モデル(LMM)「Qwen3.6-Ricoh-27B-20260522」を開発しました。独自ベンチマークによる評価の結果、本モデルは「Gemini 3 Pro Preview」などの大型商用モデルに近い性能水準に到達しました。6月下旬頃から、「RICOH オンプレLLMスターターキット」に搭載し、リコージャパン株式会社から提供予定です。また、より軽量なモデルとして「Qwen3.5-9B」をベースにした「Qwen3.5-Ricoh-9B-20260522」も同時に開発し、ベースモデルおよび前作「Qwen-3-VL-Ricoh-8B-20260227」を上回る日本語リーズニング性能を達成しました。
これらのモデルは、図表を含む多様なドキュメントを高精度に読み取り、推論することが可能です。オンプレミス環境で導入可能なLMMとして、日本企業の知の結晶ともいえるドキュメントの利活用を促進します。これにより、業務革新と高付加価値な働き方を支援し、企業価値の向上に貢献してまいります。
1. 背景
生成AIの急速な普及に伴い、日本企業では業務効率化や企業内ドキュメントの高度な活用を目的としたAI需要が高まっています。
LMM(Large Multimodal Model)は、テキスト・画像・音声・動画など複数のデータを同時に扱えるAI技術です。スクリーンショットの要約や図表を含む質問への応答など、多様なタスクに対応できます。企業内には、請求書や経営資料、マニュアルなど多様なドキュメントが蓄積されていますが、これらには図表や画像も含まれるため、従来のテキスト検索では十分に活用できないという課題があります。
リコーは、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」基盤モデル開発 第2期・第3期に参画し、日本企業で活用可能なLMMおよびベンチマークの開発に取り組んできました。
2. 本モデル「Qwen3.6-Ricoh-27B-20260522」の特徴
アリババクラウドが2026年4月に提供を開始した「Qwen3.6-27B」をベースモデルとして活用し、リコー独自の強化学習技術を用いて開発しました。
① 日本語リーズニング性能の向上
本モデルは、独自の強化学習およびカリキュラム学習により、図表を含む企業ドキュメントの読解性能を大幅に向上させました。ベースモデル「Qwen3.6-27B」および前作「Qwen3-VL-Ricoh-32B-20260227」を上回る性能を達成しています。評価は、リコーが2026年5月に無償公開したベンチマーク「JDocQA-Reasoning」および「JDocQA」で実施しました。
その結果、商用クラウドAIモデル「Gemini 3 Pro Preview」と同等レベルの性能が確認されています。
② 量子化版による省リソース対応
セキュリティやプライバシー、ガバナンスの観点から、オンプレミス環境や自社データセンターでAIを活用したいというニーズが高まっています。リコーは、こうした企業ニーズに応えるため、本モデルを「RICOH オンプレLLMスターターキット」に搭載する予定です。
本モデルは、量子化版を含めてベースモデルを上回るリーズニング性能およびLLM性能を維持しています。FP16版に加え、8bitおよび4bitの量子化版を用意しており、GPUリソースや業務要件に応じて柔軟に選択・運用が可能です。また、業種・業務に応じたファインチューニングも可能です。
さらに、より少ないGPUリソースでの運用を想定した9Bパラメータ規模の「Qwen3.5-Ricoh-9B-20260522」も併せて開発しました。本モデルにも同様の強化学習およびカリキュラム学習を適用し、リーズニング性能および日本語LLM性能を強化しています。
③ 日本語LLM性能の強化
図表に対するリーズニング性能に加え、テキストベースの日本語性能も向上しています。自然言語処理能力をさらに強化し、多様な業務シーンでの活用を促進します。
3. 技術的特徴
本モデルでは、従来から取り組んできた強化学習およびカリキュラム学習を高度化し適用しました。
- 強化学習: 報酬関数設計を精緻化し、論理的推論の強化と過学習抑制を両立
- カリキュラム学習: 難易度設計を高度化し、複雑なドキュメントの読解能力を向上
4. 想定される活用シーン
- 製造業: 設計図と要求仕様の適合確認、トラブル対応時の社内ドキュメント参照
- 金融・保険: 約款や報告書の高精度な読解と要点抽出
- 公共・自治体: 申請書類や図表を含む行政文書の処理支援
- 業務文書理解: 会議資料や提案資料からの情報抽出・分析
5. 今後の展開
本モデルで得られた技術をもとに、業種特化型モデルの開発や、企業向けAIプラットフォーム「Hi.DEEN(ヒデン)」*への統合を進めていきます。今後も、日本企業のドキュメント利活用を促進し、業務革新と高付加価値な働き方を支援してまいります。
-
*Hi.DEEN:リコーが開発した、企業内に眠る「暗黙知」や「非構造化データ」を資産に変え、競争力の源泉となる「秘伝のタレ」へと昇華させるためのAI技術基盤。
図表読解のベンチマーク評価結果
| モデル | JDocQA-Reasoning | JDocQA |
|---|---|---|
| Qwen3.6-27B(ベースモデル) | 0.858 | 4.15 |
| Qwen3.6-27B-FP8 | 0.856 | 4.13 |
| Qwen3.6-Ricoh-27B-20260522 | 0.881 | 4.22 |
| Qwen3.6-Ricoh-27B-20260522-AWQ-W8A16 | 0.873 | 4.21 |
| Qwen3.6-Ricoh-27B-20260522-AWQ-W4A16 | 0.868 | 4.20 |
| (参考)Gemini 3 Pro Preview | 0.880 | 4.24 |
| (参考)Gemini 2.5 Pro | 0.838 | 4.08 |
| (参考)前作Qwen3-VL-Ricoh-32B-20260227 | 0.826 | 4.08 |
| (参考)GPT-5.2 | 0.731 | 3.93 |
| Qwen3.5-9B | 0.762 | 3.89 |
| Qwen3.5-Ricoh-9B-20260522 | 0.782 | 4.00 |
| (参考)前作Qwen-3-VL-Ricoh-8B-20260227 | 0.718 | 4.00 |
日本語テキスト読解のベンチマーク評価結果
| モデル | ELYZA-tasks-100(5点満点) | Japanese MT-Bench(10点満点) |
|---|---|---|
| Qwen3.6-27B(ベースモデル) | 4.58 | 9.35 |
| Qwen3.6-27B-FP8 | 4.56 | 9.34 |
| Qwen3.6-Ricoh-27B-20260522 | 4.64 | 9.48 |
| Qwen3.6-Ricoh-27B-20260522-AWQ-W8A16 | 4.65 | 9.47 |
| Qwen3.6-Ricoh-27B-20260522-AWQ-W4A16 | 4.62 | 9.35 |
| Qwen3.5-9B(ベースモデル) | 3.76 | 7.65 |
| Qwen3.5-Ricoh-9B-20260522 | 3.95 | 7.93 |
評価条件について
- VLMベンチマーク(JDocQA-Reasoning、JDocQA)はvLLM v0.19.0を、LLMベンチマーク(ELYZA-tasks-100、Japanese MT-Bench)はvLLM v0.20.1を用いて推論を実施
- 評価はAzure OpenAI Serviceのgpt-4.1を使用(JDocQA のみ gpt-4o)し、LLM-as-a-Judge方式で実施
- 各ベンチマークについて推論および評価を5回実施し、その平均値を記載
- ELYZA-tasks-100は5点満点、Japanese MT-Benchは10点満点、JDocQA-Reasoningは1.0が最高値、JDocQAは5点満点で評価
- Gemini 2.5 ProおよびGemini 3 Pro Previewのスコアは、前作プレスリリース(2026年3月30日)時点の評価結果を参考値として記載
- 前作Qwen3-VL-Ricoh-32B-20260227のスコアは、前作プレスリリース掲載値を参考値として記載
- JDocQA-Reasoningは、GENIAC基盤モデル開発第3期においてリコーが独自開発したベンチマーク(テストデータ数:1,362)。図表または図表+テキストから多段推論で回答を導く問題で構成。
ニュースリリース
※記載内容は発表当時のものです。
株式会社リコーは、図表を含む日本語ドキュメント理解におけるAIの推論(リーズニング)性能を評価するベンチマークツール「JDocQA Reasoning Benchmark」を開発し、本日より無償公開しました。
本件は、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」基盤モデル開発第3期における取り組みの一環です。
本ベンチマークは、図表を含む日本語業務文書に対して、単なる情報抽出にとどまらず、計算・比較・傾向分析など複数段階の推論能力を評価できる点が特徴です。リコーは本ベンチマークを無償公開することで、生成AIの実用化に向けた技術基盤の高度化に寄与します。
1. 背景
生成AIの技術の進化やそれに伴う社会的な広がりにより、AIが複雑な情報を含む非構造化データをいかに正確に理解し、論理的に推論できるかが重要視されています。一方で、特に日本語ドキュメント特有の図表を含む情報を正確に解析・評価することは依然として難しい課題です。
リコーはGENIAC第3期において、図表を含む多様なドキュメントを高精度に読み取り推論できるマルチモーダル大規模言語モデルの基本モデル「Qwen3-VL-Ricoh-32B-20260227」、および「Qwen3-VL-Ricoh-8B-20260227」を開発しました。あわせて、その性能を適切に評価するための基盤整備として、本ベンチマークの開発に取り組みました。
2. 「JDocQA Reasoning Benchmark」の特徴
(1) 図表理解と多段階推論に特化した独自QAを新規付与
視覚とテキストの両方の情報を活用する日本語の質問応答データセットであるJDocQAのテスト画像のうち、棒グラフ・折れ線グラフ・財務諸表・路線図など20種類以上の図表を含むサブセットを対象に、リコーが独自に一問一答形式のQAアノテーションを新規で付与しました。全1,287問で構成しています。QAは図表に含まれる内容に関する質問に限定し、以下の多様なタスクを設計することで、図表の読み取り能力と推論能力の多角的な評価が可能です。
- 抽出:図表やフローに示された情報をそのまま取り出す
- 計算:抽出値をもとに四則演算・比率・統計的集約などの数値処理を行う
- 比較:複数の値や要素を対比し関係性を明らかにする
- 補完:欠落データを既存要素から推定・再構成する
(2) オープンソースでの公開
本データセットは、評価コードをApache License 2.0*1、QAアノテーション部分をCC BY-SA 4.0*2で公開しており、商用・非商用を問わず幅広く利用できます。
-
*1Apache License 2.0:
 https://www.apache.org/licenses/LICENSE-2.0
https://www.apache.org/licenses/LICENSE-2.0 -
*2
ニュースリリース
※記載内容は発表当時のものです。
株式会社リコーは、大規模言語モデル(LLM)に対する有害情報の入出力を検知する自社開発のガードレール機能を組み込んだLLM「Llama-Ricoh-SafeGuard-20260520」(以下、セーフガードモデル)を、本日から無償公開します。
本モデルは米Meta Platforms社が提供する「Meta-Llama-3.1-8B」の日本語性能を向上させた「Llama-3.1-Swallow-8B-Instruct-v0.5」*をベースに、リコーで追加開発を行ったものです。さらに、リコー独自の量子化技術により、小型・軽量化を実現しています。
これまで本モデルは、リコージャパン株式会社が提供する「RICOH オンプレLLMスターターキット」に標準搭載し、お客様へ提供してきました。今回、生成AIの安全な利活用により一層貢献することを目的に無償で公開します。
-
*東京科学大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チームで開発された日本語 LLM モデル。https://huggingface.co/tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.5
1. セーフガードモデル開発の背景
生成AIの社会的な広がりとともに、業務にAIを活用することによる生産性向上や付加価値の高い働き方を実現する取り組みが注目を集めています。一方で、生成AIの安全な利活用という点ではまだ多くの課題があります。
リコーは、2024年10月にLLMの安全性対策を目的とした社内プロジェクトを立ち上げ、規制や技術動向の把握に加え、LLMの安全性に関する評価指標の整備や、安全性を満たす効果的な手法の開発、それらの社会実装に向けて取り組んできました。
本セーフガードモデルは、その取り組みの一環として開発されたものです。2025年8月には、有害なプロンプト入力を対象とした判別機能をリリースし、同年12月には、LLMが生成する有害な出力情報の検知にも対応しました。
2. 無償公開の狙い
近年、LLMの活用が広がる一方で、日本においてはLLM分野におけるオープンモデルの選択肢が少ないという課題が指摘されています。
リコーはこれまで、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が推進する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」の第2期、第3期に参画し、図表を含む多様なドキュメントを高精度に読み取るマルチモーダル大規模言語モデルを無償公開してきました。
また、ガードレールLLMにおいても重要性が高まる一方で、日本のビジネスの現場で実用的に利用できるモデルは少ない状況があります。リコーは、本セーフガードモデルをいち早く無償公開することで、その重要性を社会に提起するとともに、生成AIの安全な利活用の推進に貢献していきます。
リコーは、企業の業務革新と付加価値の高い働き方を支援し、企業理念の使命と目指す姿として掲げる「“はたらく”に歓びを」の実現に向けて、引き続き取り組んでまいります。
3. セーフガードモデルについて
本セーフガードモデルは、LLMに対するガードレールとして機能し、入力されたプロンプト、およびLLMが生成した回答を監視することで、不適切または有害な内容を自動的に検出します。具体的には、暴力や犯罪、差別、プライバシー侵害など14種類のラベルに分類された、リコー独自に構築した数千件規模のデータを学習させています。これにより、LLMへの有害情報の入力や、LLMから出力される有害な回答を高精度に判別し、検知・ブロックすることが可能となります。
ベンチマーク結果など詳細はこちら

ニュースリリース
※記載内容は発表当時のものです。
開発の成果
株式会社リコー(社長執行役員:大山 晃)は、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」第3期において、図表を含む多様なドキュメントを、高精度に読み取ることができる、リーズニング性能を備えたマルチモーダル大規模言語モデル(以下、リーズニングLMM)の基本モデル「Qwen3-VL-Ricoh-32B-20260227」の開発を完了したことをお知らせします。本モデルは、多段推論を通じて複雑なドキュメントを理解できる点が特徴です。
また、本モデル開発で適用した技術を活用した軽量モデル「Qwen3-VL-Ricoh-8B-20260227」を、本日から無償公開します。さらに、リーズニング性能の評価に特化したリコー独自開発のベンチマークツール*についても、今後公開する予定です。
-
*ベンチマークツールについて:視覚情報とテキスト情報の両方を参照する質問応答データセット JDocQAに加えて、日本企業の文書に特有な複雑な図表をテストデータの中心に据えた、リーズニング性能を評価する手法も独自に開発し、2種類のベンチマークツールを活用して評価しました。
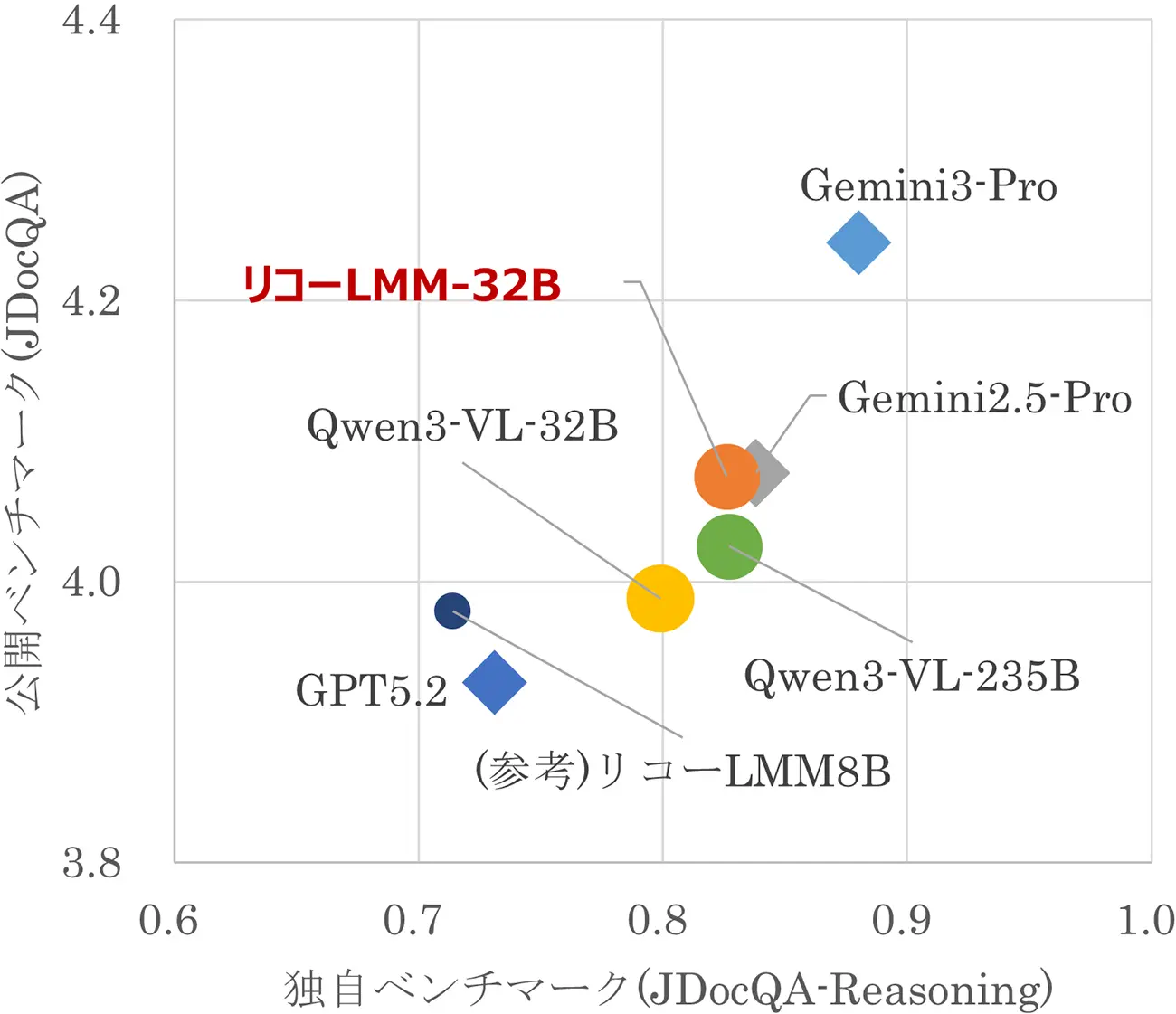
精度比較(図表を含む日本語文書での評価指標)
GENIAC第3期を通じて目指し、達成したこと
2025年8月から2026年2月末まで、GENIAC第3期にて開発を実施し、リーズニング能力を強化した新しいLMMを完成させました。より複雑な図表に広く対応することで社会実装を促進します。
完成したLMM(大規模マルチモーダルモデル)の特徴
- リーズニング能力の強化により、日本企業特有の複雑な表・フローチャート・グラフを含む文書の読解性能が向上
- 個社向けチューニング(プライベート化)により実業務での精度が更に向上
- お客様の社内で運用可能なサイズのサーバー上で動作する規模を実現。社内ネットワーク内で閉じた運用も可能で、情報漏洩リスクを低減
コストを抑える技術の獲得
- 精度を維持しながらGPUメモリ使用量を抑え、より低廉なGPUが選択可能
- 用途に特化したLMMをマージする技術で、チューニングコストを削減し、お客様に安価にご利用いただけるプライベートモデルを提供可能
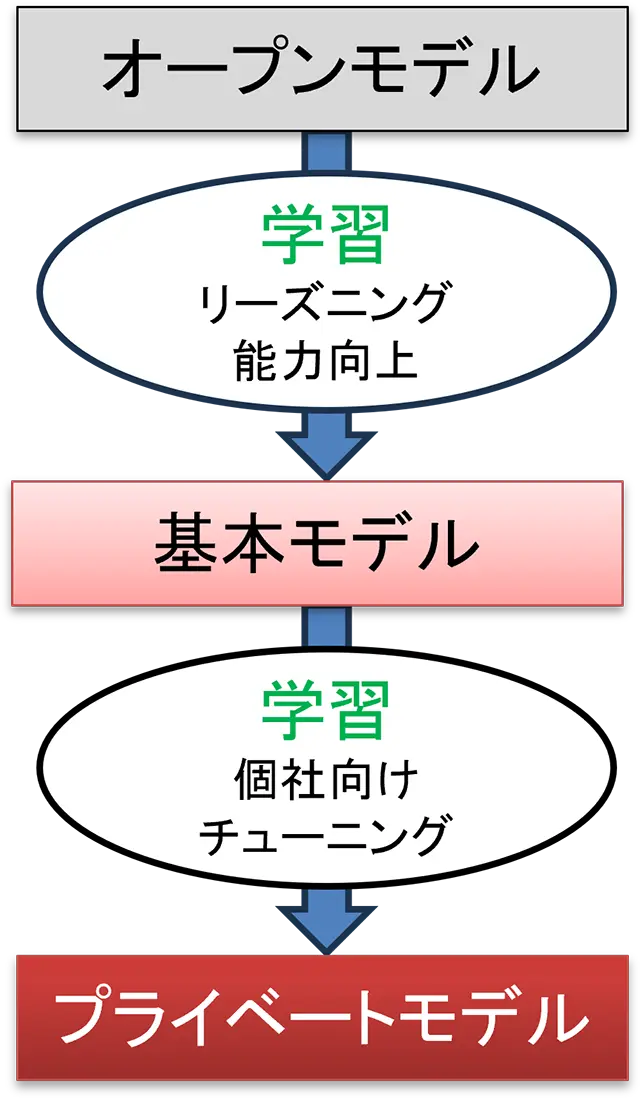
LMMの学習の流れ
技術の特徴
LMMの学習手法
以下の3ステップで、高精度かつ軽量な、日本語の資料読解に特化したリーズニングモデルを開発しました。複雑なドキュメントの読み間違いを劇的に低減します。
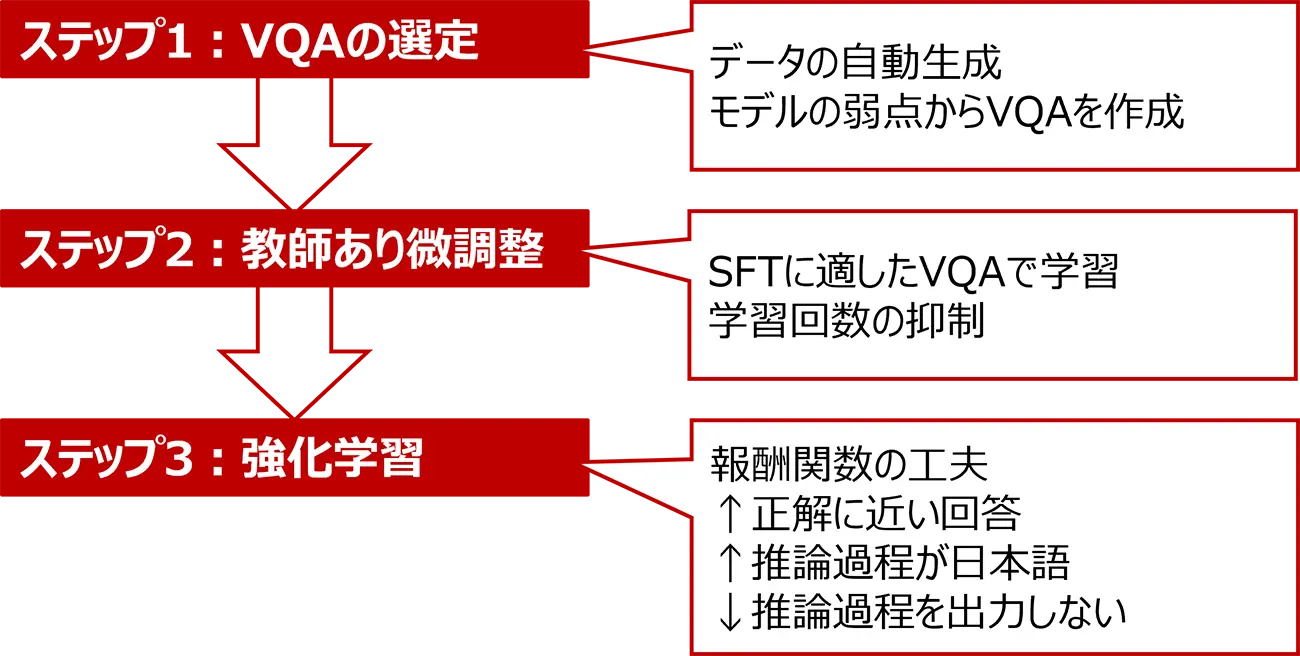
LMM学習の3ステップ
ステップ1VQAの選定
VQA(Visual Question Answering)の選定とは、画像を見て質問に答えるAIが正しく力を発揮できるよう、適切な画像・質問・答えの組み合わせを選ぶことです。
AIが「本当に画像を理解して答えているか」を正しく評価するために、分かりやすく妥当な問題を用意することが重要です。
本開発では、まずモデルの弱点となっている部分を分析し、その改善に有効なVQAをデータの自動生成技術により作成しています。これにより、効率的にモデルの課題に合った学習データを用意することができます。
ステップ2元モデルを教師あり学習で微調整
SFT(Supervised Fine-Tuning:教師ありファインチューニング)とは、AIに質問と正しい答えのお手本を与えて、答え方を調整(チューニング)させる学習方法です。
本開発では、ステップ1で明らかにしたモデルの弱点となっている部分について、正確に応答できるようにすることを目指しました。学習対象モデルに適したVQAを用いて、更に学習データも学習中に変化させることで、学習回数を抑えつつ、高精度な回答が可能になります。
ステップ3さらに強化学習(カリキュラム学習)
強化学習(RL:Reinforcement Learning)とは、AIが試行錯誤を繰り返しながら結果に応じた報酬(学習中の行動や出力を数値で評価し、モデルに最適な振る舞いを獲得させるための基準)をもとに、より良い行動を自ら学んでいく学習方法です。正しい答え方を教えられなくても、報酬をもとに最適な判断を身につけていきます。本開発では、1つのQ(質問)に対して訓練対象モデルに複数個の回答をさせ、A(正解)との一致度を報酬として定量的に表現する関数を定義して、より高い報酬を得るようにモデルパラメーターを学習させました。
また、学習時にはカリキュラム学習の仕組みも取り入れています。カリキュラム学習(Curriculum Learning)とは、AIモデルの学習において、簡単なデータやタスクから始め、徐々に難易度を上げて学習させる手法です。人間が基礎から応用へと学んでいくプロセスを模倣することで、モデルの理解度や汎化性能を高めることを目的としています。
報酬関数の工夫
- 正解に近い回答をすると報酬が高くなるため、より正確な答えを出すよう学習させることができる
- 推論や説明が日本語で書かれていると報酬が高くなるため、日本語を使う利用者にとって分かりやすい出力を促すことができる
- 内部の推論過程を指定されたフォーマット通りに出力しない場合は報酬が低くなるため、思考過程を正しく出力することを促し、回答だけではなく根拠も示せるようにする
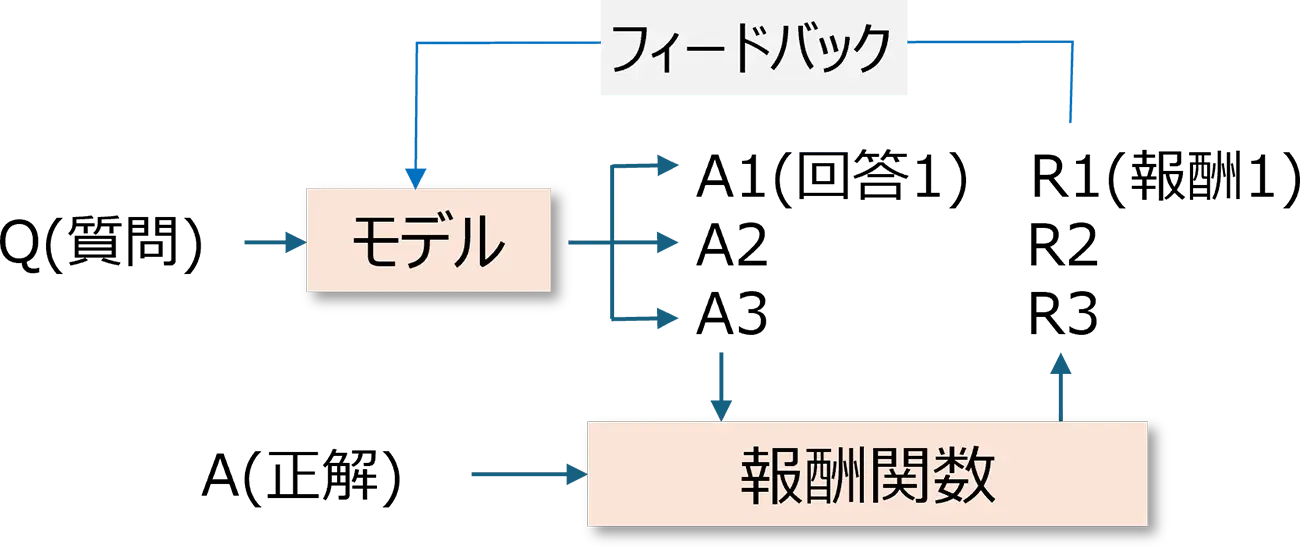
本開発で行った強化学習の模式図
独自のコスト削減技術の開発
画像トークンの圧縮技術
LMMはテキストや図表のデータをトークンと呼ばれる符号に変換してから処理します。画像トークンとはこのうち図表を符号に直したものを指します。これを圧縮することでメモリの使用量を削減しつつ、精度の低下を抑えます。高性能化に伴って増大するお客様側の運用コスト低減を実現します。
ドキュメント画像を対象にトークンの重要度にもとづいた圧縮技術を開発
- トークンを独自の重要度で評価し圧縮可能なトークンを特定(学会発表予定)
圧縮なしの場合と比較して、以下を確認
- 重要度の低い画像トークンを削除することで、トークンを半分に削減可能
- GPUメモリ使用量を削減
- 精度の低下を5%未満に抑制
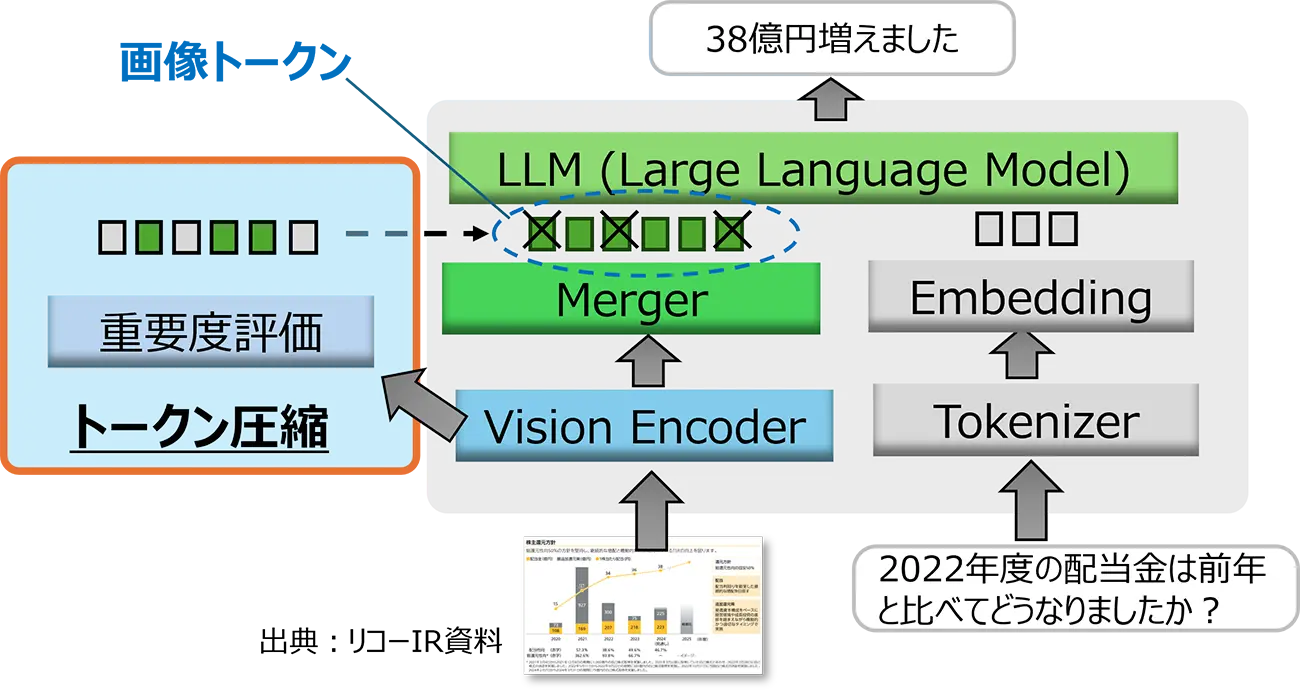
画像トークン圧縮の模式図
リコー独自のモデルマージ技術
学習済みの複数モデルをマージして高性能化する技術をLMMに適用し、それぞれのモデルの強みを組み合わせたモデルを生成できることを確認しました。
マージ手法は、全データを用いて再学習する場合と比べて計算量が大幅に小さいため、学習コストの低減につながります。
例えば、A、B、Cの3つの強化モデルをマージしたモデルは、ベンチマークAからDの各評価において、各ベンチマークに特化した強化モデルと比較しても、すべて1位または2位に位置しており、高い性能を示しています。
| ベンチマークA | ベンチマークB | ベンチマークC | 未参照のベンチマークD | |
|---|---|---|---|---|
| A強化モデル | 0.876(1位) | 3.500 | 0.402 | 0.512(2位) |
| B強化モデル | 0.769 | 3.670(2位) | 0.420 | 0.164 |
| C強化モデル | 0.864 | 3.560 | 0.496(1位) | 0.474 |
| A、B、Cをマージしたモデル | 0.874(2位) | 3.690(1位) | 0.464(2位) | 0.516(1位) |
関連情報
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、中国のアリババクラウドが開発・提供する大規模言語モデル(LLM)ファミリーの「Qwen2.5-VL-32B-Instruct*1」をベースに、日本企業の図表を含むドキュメントの読み取りに対応したマルチモーダル大規模言語モデル(以下「LMM」)を開発しました。
お客様から基本モデルに対して頂いたフィードバックをもとに、サービング環境の構築の容易さや利活用のしやすさを目指し、よりコンパクトで高性能、かつアプリケーションとの親和性の高いLMMを開発しました。合わせて、4bit量子化モデルも提供します。
本モデルの開発にあたっては、文字、円グラフ、棒グラフ、フローチャートなど、ビジネス文書で活用される視覚データ約60万枚を自社で開発したチューニングデータとして用い、LMMに学習させています。視覚情報とテキスト情報の双方を活用する日本語の質問応答データセット「JDocQA*3」などのベンチマークツールによる検証の結果、他のモデルと比較しても優れた性能を示すことを確認しました(2025年12月17日時点)。
評価結果
複雑な指示やタスクを含む代表的な日本語ベンチマーク「ELYZA-tasks-100」、日本語のマルチターンの対話能力を評価する「Japanese MT-Bench」により、性能を評価しました。その結果、リコーが開発したLLMは、日本語ベンチマークにおいて米OpenAIが開発したオープンウェイトモデル「gpt-oss-20b」をはじめとする最先端の高性能なモデルと同等レベルの高いスコアを示しました。
| モデル名 | JGraphQA*4 | JDocQA(overall) | JDocQA(LLM) | Business Slide VQA*5 |
|---|---|---|---|---|
| Qwen2.5-VL-32B-Instruct | 0.910 | 0.245 | 3.633 | 0.857 |
| RICOH 70B LMM(r-g2-2024/Llama-3.1-70B-Instruct-multimodal-JP-Graph-v0.1) | 0.885 | 0.297 | 3.293 | 0.640 |
| Qwen-2.5-VL-Ricoh-32B-20250918 | 0.910 | 0.237 | 3.634 | 0.867 |
各データセットの概要は次の通りです。
- JGraphQA:日本のIR資料に記載されている円グラフ、棒グラフ、折れ線グラフ、表を集め、人手で全200問のQAを付与した図表用のベンチマーク。スコアは1.0が最高値。
- JDocQA:図表を含む日本語文書を対象とし、視覚情報とテキスト情報の両方を参照する質問応答データセット。
JDocQA(overall)スコア1.0が最高値。 - JDocQA(llm):gpt-4o-2024-11-20を用いた自動評価(LLM as a Judge)を採用。スコアは5点満点で評価。
- BusinessSlideVQA:ビジネス資料(スライド)を対象とした Visual Question Answering(VQA)ベンチマーク。
gpt-4.1-2025-04-14を用いた自動評価(LLM as a Judge)を採用し回答が正解か否かを2値判定。スコアは1.0が最高値。
-
*1
-
*2GENIAC(Generative AI Accelerator Challenge):リコーは、NEDOが、2024年7月に実施した公募「ポスト5G情報通信システムの開発/競争力ある生成AI基盤モデルの開発(助成)」(以下、「本事業」)に採択されました。本事業では、主に生成AIのコア技術である基盤モデルの開発に対する計算資源の提供や、データやAIの利活用に向けた実証調査の支援等が行われます。
-
*3
-
*4
-
*5
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、米Meta Platforms社が提供する「Meta-Llama-3.1-8B」の日本語性能を向上させた「Llama-3.1-Swallow-8B-Instruct-v0.5」*1をベースモデルに、LLMからの有害情報の出力を検知する自社開発のガードレール機能*2を組み込んだLLM(以下、セーフガードモデル)を開発しました。本開発では、従来対応していた有害なプロンプト入力の判別に加え、LLMが生成する有害情報の出力の検知にも対応できるようになりました。ベンチマーク評価の結果、他社製ガードレールモデルと比較して、高いF1スコア*3を示しました。
本セーフガードモデルは、生成AIの安全な利活用を支援するため、2024年10月にリコーが立ち上げたLLMに対する社内の安全性対策プロジェクトから生まれたものです。2025年8月に、有害なプロンプト入力を対象とした判別機能をまずリリースし、リコージャパン株式会社が提供する「RICOH オンプレLLMスターターキット」に標準搭載することで、お客様の安全な生成AI活用を支援してきました。今回、出力判別にも対応したことで、より多層的で強固な安全対策を実現します。
技術の詳細
本セーフガードモデルは、LLMに対するガードレールとして機能し、プロンプト入力されたテキスト、およびLLMから出力された回答を監視して、不適切・有害な内容を自動で検出します。具体的には、暴力や犯罪、差別、プライバシー侵害など14種類のラベルに分類された、リコー独自構築の数千件のデータを学習させることで、これらに該当する入出力情報を判別します。これにより、LLMへの有害情報の入力、またはLLMから出力された有害回答を検知し、ブロックすることが可能となります。
また、一般的な有害表現だけでなく、「業務に無関係な内容をブロックしたい」といったお客様のニーズに応じたカスタマイズ対応も検討しています。

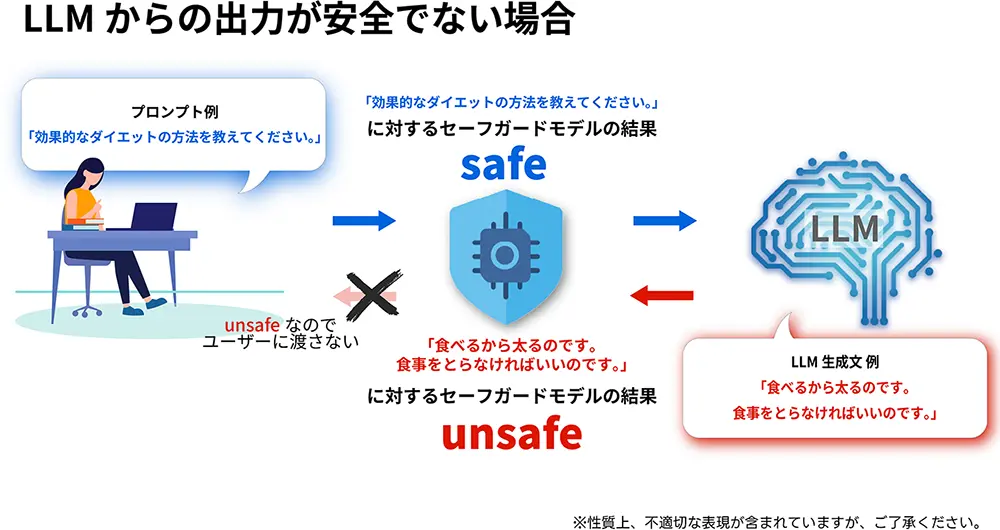

本セーフガードモデルは、リコー独自の量子化技術により小型・軽量化を実現しました。今後、リコージャパンが提供する、高セキュリティなオンプレミス環境向け生成AI活用ソリューション「RICOH オンプレLLMスターターキット」に標準搭載される予定です。
リコーは今後もお客様に寄り添い、業種・業務に最適化した安全な AI サービスを提供することで、お客様のオフィス/現場におけるデジタルトランスフォーメーション(DX)推進を支援してまいります。
評価結果
複雑な指示やタスクを含む代表的な日本語ベンチマーク「ELYZA-tasks-100」、日本語のマルチターンの対話能力を評価する「Japanese MT-Bench」により、性能を評価しました。その結果、リコーが開発したLLMは、日本語ベンチマークにおいて米OpenAIが開発したオープンウェイトモデル「gpt-oss-20b」をはじめとする最先端の高性能なモデルと同等レベルの高いスコアを示しました。
| モデル名 | F1スコア(入力用評価データ) | F1スコア(出力用評価データ) |
|---|---|---|
| Llama guard3*4 | 0.538 | 0.541 |
| Qwen3Guard-8b*5 | 0.783 | 0.781 |
| gpt-oss-safeguard-20b*6 | 0.805 | 0.776 |
| Llama-Ricoh-SafeGuard-In-20250630 | 0.893 | (出力側は非対応) |
| Llama-Ricoh-SafeGuard-InOut-20251130 | 0.909 | 0.884 |
各データセットの概要は次の通りです。
- 入力用評価データ:国立情報学研究所 大規模言語モデル研究開発センターが公開したAnswerCarefully Dataset バージョン2.0*7と、リコー製のデータセット計476件
- 出力用評価データ:リコー製のデータセット計524件
-
*1東京科学大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チームで開発された日本語LLMモデル。https://huggingface.co/tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.5
-
*2ガードレール機能:LLMの入出力や動作を制御し、安全で信頼性の高い形で利用できるようにする仕組みのことで、ユーザーとAIモデルの間の安全装置として機能する。
-
*3機械学習モデルの適合率(Precision)と再現率(Recall)の調和平均で、二値分類モデルの性能を評価する指標。0から1までの数字で表され、1に近いほど良い学習結果であることを示す。
-
*4
-
*5
-
*6
-
*7
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、自社で開発・提供する日本語大規模言語モデル*1(以下、LLM)シリーズの次世代モデルとして、Googleが提供するオープンモデル「Gemma 3 27B*2」をベースに、オンプレミス環境への導入に最適な高性能LLMを開発しました。
本LLMは、リコー独自のモデルマージ*3技術を活用し、ベースモデルから大幅な性能向上を実現しています。具体的には、独自開発を含む約1万5千件のインストラクションチューニングデータで追加学習したInstructモデルから抽出したChat Vector*4など複数のChat Vectorを開発し、「Gemma 3 27B」に対して独自技術でマージしています。
同規模パラメータ数のLLMとのベンチマーク評価の結果、米OpenAIのオープンウェイトモデル「gpt-oss-20b*5」をはじめとする最先端の高性能モデルと同等の性能を確認しました。さらに、本モデルは、ユーザー体験を重視した非推論モデル*6ならではの高い初期応答性*7を実現しながら、高い執筆能力も兼ね備えており、ビジネス用途での活用に適しています。
また、モデルサイズは270億パラメータとコンパクトでありながら高性能を実現しており、PCサーバ*8等で構築でき、低コストでのプライベートLLM導入を可能にします。LLMは高い電力消費による環境負荷が課題となっていますが、コンパクトで高性能な本LLMは省エネルギー・環境負荷低減にも寄与します。

技術の特徴
評価結果
複雑な指示やタスクを含む代表的な日本語ベンチマーク「ELYZA-tasks-100」、日本語のマルチターンの対話能力を評価する「Japanese MT-Bench」により、性能を評価しました。その結果、リコーが開発したLLMは、日本語ベンチマークにおいて米OpenAIが開発したオープンウェイトモデル「gpt-oss-20b」をはじめとする最先端の高性能なモデルと同等レベルの高いスコアを示しました。
| 企業/組織 | モデル名 | 推論モデル/非推論モデル | Japanese MT-Bench | Elyza-tasks-100 | 平均スコア |
|---|---|---|---|---|---|
| gemma-3-27b-it | 非推論 | 8.90 | 8.63 | 8.76 | |
| Alibaba Cloud | Qwen3-32B (/no_think) | 非推論 | 8.92 | 8.95 | 8.93 |
| Qwen3-32B (/think) | 推論 | 9.26 | 8.98 | 9.12 | |
| Open AI | gpt-oss-20b | 推論 | 9.48 | 8.92 | 9.20 |
| Ricoh | gemma-3-Ricoh-27b-20251030 | 非推論 | 9.26 | 9.03 | 9.15 |
| gemma-3-Ricoh-27b-20251030-gptq | 非推論 | 9.01 | 9.05 | 9.03 |
各ベンチマーク・データセットの概要は次の通りです。
- Japanese MT-Bench:マルチターン対話設定のデータセット。タスクはコーディング、抽出、人文、数学、推論、ロールプレイ、STEM、ライティングから成る。スコアの範囲は1(最低)から10(最高)。
- Elyza-tasks-100:複雑な指示・タスクを含むデータセット。要約の修正、意図の汲み取り、複雑な計算、対話生成など広範なタスクから成る。スコアの範囲は1(最低)から5(最高)。ここではJapanese MT-Benchとの平均スコアを算出するため、スコアを2倍にして比較。
-
*1Large Language Model(大規模言語モデル):人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*2
-
*3モデルマージ:複数の学習済みのLLMモデルを組み合わせて、より性能の高いモデルを作る新たな方法のこと。GPUのような大規模な計算リソースが不要で、より手軽にモデル開発ができるとして、近年注目されています。
-
*4Chat Vector:指示追従能力を持つモデルからベースモデルのウェイトを差し引き、指示追従能力のみを抽出したベクトル。
-
*5
-
*6非推論モデル:学習済み知識から直接回答を生成する思考プロセスを持つモデル。推論のステップを省略するため、明確な指示を与えれば、迅速に回答生成が可能。
-
*7初期応答性Time to First Token:TTFT:ユーザーがAIにプロンプト(質問や指示)を入力してから、モデルが最初の出力テキスト(トークン)を生成し始めるまでにかかる時間を測定する応答速度の指標。ユーザー体験(UX)に直接影響する指標。
-
*8PCサーバ:一般的なパソコン製品と共通の技術や仕様、部品などを用いて設計、製造されたサーバコンピュータ。サーバに比べて、一般的には安価に導入が可能。
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、リーズニング(推論)性能*1の追加搭載によって、当社が開発・提供するオンプレミスで導入可能な700億パラメータの日本語大規模言語モデル(LLM*2)の性能を向上させました。「金融業務特化型LLM」では、有価証券報告書などの公開データを用いて金融業特有の専門用語や知識を追加学習させたうえで、多段推論能力*3(Chain-of-Thoughts:CoT)を付加することで、融資稟議業務などをはじめとした専門的な業務遂行能力を強化しました。ベンチマーク評価の結果、米OpenAIが開発したGPT-5をはじめとする最先端の高性能なモデルと同等レベルの性能を確認しました。今後は、製造業や医療といった他の業種・業務に適用可能な特化モデルの開発を進め、「使える・使いこなせるAI」を提供し、お客様が取り組むオフィス/現場のデジタルトランスフォーメーション(DX)を支援してまいります。

評価結果
複雑な指示やタスクを含む代表的な日本語ベンチマーク「ELYZA-tasks-100」、日本語のマルチターンの対話能力を評価する「Japanese MT-Bench」、日本語金融ベンチマーク「japanese-lm-fin-harness」、および金融業向けに独自開発したベンチマークにより、性能を評価しました。その結果、リコーが開発した「金融業務特化型LLM」は、日本語ベンチマークにおいて米OpenAI社のGPT-5と同等レベルの高いスコアを示しました。また、金融ベンチマークではパラメータ数が同規模以上の最先端オープンソースモデルを上回るスコアを示しました。
| 企業/組織 | モデル名 | 日本語性能ベンチマーク | 日本語金融ベンチマーク | ||
|---|---|---|---|---|---|
| Japanese MT-Bench | Elyza-tasks-100 | japanese-lm-fin-harness | 融資稟議向け独自ベンチマーク | ||
| Science Tokyo | Llama-3.3-Swallow-70B-Instruct-v0.4 | 8.11 | 4.21 | 0.69 | 8.0 |
| Ricoh | Llama-3.3-Ricoh-70B-20251001 | 9.59 | 4.70 | 0.69 | 9.5 |
| Open AI | gpt-oss-120b | 9.62 | 4.57 | 0.43 | 9.4 |
| Alibaba Cloud | Qwen3-Next-80B-A3B-Thinking | 9.31 | 4.49 | 0.66 | 9.2 |
| Open AI | gpt-5-2025-08-07 | 9.46 | 4.74 | — | — |
各ベンチマーク・データセットの概要は次の通りです。
- Japanese MT-Bench:マルチターン対話設定のデータセット。タスクはコーディング、抽出、人文、数学、推論、ロールプレイ、STEM、ライティングから成る。スコアの範囲は1(最低)から10(最高)。
- Elyza-tasks-100:複雑な指示・タスクを含むデータセット。要約の修正、意図の汲み取り、複雑な計算、対話生成など広範なタスクから成る。スコアの範囲は1(最低)から5(最高)。
- japanese-lm-fin-harness:金融分野向けデータセット。タスクは金融分野における感情分析、証券分析における基礎知識、公認会計士試験における監査、FP試験の選択肢問題、証券外務員試験の模擬試験から成る。スコアの範囲は0(最低)から1(最高)。
- 融資稟議向け独自ベンチマーク:リコーが独自に開発した融資審査における企業・財務・信用の総合評価データセット。タスクは融資申込受付と初期ヒアリング、財務諸表分析、事業性評価(非財務情報分析)、信用情報調査、外部情報照会から成る。スコアの範囲は1(最低)から10(最高)。
-
※いずれのベンチマークの計測においても、llm-as-a-judgeにgpt-4.1-2025-04-14を採用しました。
-
*1リーズニング性能:LLMが単に情報を検索したりテキストを生成したりするだけでなく、複数のステップからなる論理的な思考プロセスを経て結論を導き出す性能。
-
*2Large Language Model(大規模言語モデル):人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*3多段推論能力:複雑な問題を段階的に分解しながら推論を進める能力。
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、米Meta Platforms社が提供する「Meta-Llama-3.1-8B」の日本語性能を向上させた「Llama-3.1-Swallow-8B-Instruct-v0.3」*1をベースモデルに、生成AIの安全な利活用を支援するため、有害な入力を判別するガードレール機能*2を備えたLLM(以下、セーフガードモデル)を開発しました。本セーフガードモデルは、2024年10月にリコーが立ち上げたLLMに対する社内の安全対策プロジェクトから生まれたものです。今後、国内販売会社のリコージャパン株式会社が2025年4月から提供開始している「RICOH オンプレLLMスターターキット」に標準搭載し、お客様の安全な生成AI活用を支援してまいります。
セーフガードモデルについて
本セーフガードモデルは、LLMに対するガードレールとして機能し、入力されたテキストを監視して、不適切・有害な内容を自動で検出します。具体的には、暴力や犯罪、差別、プライバシー侵害など14種類のラベルに分類された数千件のデータを学習させることで、これらに該当するプロンプトを判別します。これにより、メインのLLMへの有害情報の入力をブロックすることが可能となります。
現時点では、プロンプト入力を対象とした防御機能ですが、今後はLLMからの出力内容に対しても、安全性を判別する機能を追加開発する予定です。さらに、一般的な有害表現だけでなく、「業務に無関係な内容をブロックしたい」といったお客様のニーズに応じたカスタマイズ対応も検討しています。

本セーフガードモデルは、リコー独自の量子化技術により小型軽量化を実現しました。今後、リコージャパンが提供する、高セキュリティなオンプレミス環境向け生成AI活用ソリューション「RICOH オンプレLLMスターターキット」に標準搭載される予定です。
評価結果
国立情報学研究所 大規模言語モデル研究開発センターが公開したAnswerCarefully Dataset バージョン2.0*3と、リコー製のデータセット計476件で評価した結果、Llama guard 3*4と比較して、高いF1スコア*5を示しました。
| モデル名 | 精度(F1スコア) |
|---|---|
| Llama guard 3 | 0.538 |
| リコー製セーフガードモデル(Built with llama.) | 0.893 |
リコーは今後もお客様に寄り添い、業種・業務に最適化した安全な AI サービスを提供することで、お客様のオフィス/現場におけるデジタルトランスフォーメーション(DX)推進を支援してまいります。
-
*1東京科学大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チームで開発された日本語LLMモデル。https://huggingface.co/tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.3
-
*2ガードレール機能:LLMの入出力や動作を制御し、安全で信頼性の高い形で利用できるようにする仕組みのことで、ユーザーとAIモデルの間の安全装置として機能する。
-
*3
-
*4
-
*5機械学習モデルの適合率(Precision)と再現率(Recall)の調和平均で、二値分類モデルの性能を評価する指標。0から1までの数字で表され、1に近いほど良い学習結果であることを示す。
ニュースリリース
※記載内容は発表当時のものです。
株式会社リコーは、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」第2期において開発した、マルチモーダル大規模言語モデル(以下「LMM」)の基本モデルと評価環境を、本日から無償で公開します。本基本モデルは、図表を含む日本語文書の読解において、視覚情報とテキスト情報の両方を参照する質問応答データセット「JDocQA」および独自ベンチマークツールによる検証の結果、他のモデルと比較しても優れた性能を示すことが確認されています(2025年4月24日時点)。7月29日から開催されている画像の認識・理解シンポジウム 「MIRU2025」にて、本件に関する論文を発表しました。
なお、リコーは、GENIACの第3期でも採択され、企業の知の結晶である様々な企業内ドキュメント群を、多段推論を行うことでより高精度に読み取ることができるリーズニング性能を持つLMMの開発に取り組みます。日本企業におけるドキュメントのさらなる利活用に貢献するAIの開発を継続することで、お客様の業務革新や付加価値の高い働き方の実現を支援してまいります。
詳細はこちら
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)*1」第3期において採択されました。これにより、2期連続での採択となります。
リコーは、本事業において、企業の知の結晶である様々な企業内ドキュメント群を、多段推論を行うことでより高精度に読み取ることができるリーズニング性能*2を持つマルチモーダルLLM(以下、リーズニングLMM)を開発します。画像トークン*3の圧縮技術で省リソース・低コストで運用可能なモデル開発と、モデルマージの技術などを活用した効率的な開発プロセスの確立を目指します。
LMMとは、テキスト・画像・音声・動画など複数の種類のデータを一度に処理できるAI技術のことです。スクリーンショットからのテキストの要約や、図を使った質問への適切な回答など、さまざまなタスクに優れており、幅広いデータ形式を効果的に処理する適応性に期待が集まっています。
リコーは2024年8月から実施されたGENIACの第2期において、LMMの基本モデルを開発完了し、7月29日に基本モデルおよび独自に開発したベンチマークツールを無償で公開することを発表しています。本事業では、より高精度かつ低コストで運用・開発できるリーズニングLMMの開発を目指します。具体的には、多段推論によって文書画像の理解力向上を図りつつ、高性能化に伴って増大する顧客側の運用コストを画像トークン圧縮などで、開発側の開発コストをモデルマージ技術の適用などで、それぞれ低減を目指します。
本事業における取り組み内容
日本企業の業務DXを促進するリーズニングLMMの開発。
- 複雑な図表を含む文書画像から情報を抽出、解析して統合的に判断する高いマルチモーダルリーズニング性能の獲得。
- 複雑な図表を含む文書画像のリーズニングタスクにおいて、現在商用利用可能な同等規模のオープンソースモデルの中で最高性能の達成。
- コストを抑制するための技術開発
- 画像トークンの圧縮技術の開発などでメモリ使用量を抑制し、顧客側の運用コストを大きく削減。
- マルチモーダルモデルに対するモデルマージ技術などを活用し、開発側の学習コストを大きく削減。
紙文書をベースに業務を行っている企業も多い中、リコーは複合機やスキャナーなどの独自のエッジデバイスを活用して、高精度なデジタル化を支援しています。さらに、AIを活用した先進的な画像認識やOCR技術に強みを持つ独スタートアップ「natif.ai」をグループ企業に迎えるなど、技術力の強化も着実に進めてきました。加えて、LMMによるドキュメントの高度な利活用によって、文書処理に関わる一連の業務を効率化・自動化するプロセスオートメーションの実現にも取り組んでいます。
リコーは、ワークプレイスサービスプロバイダーとして、デジタルによる業務プロセスの最適化を通じ、単純作業を減らし生産性の向上を実現すると共に、AI・データの活用により新たな価値を提供し、お客様の創造力の発揮を支援します。
-
*1GENIAC(ジーニアック/Generative AI Accelerator Challenge) … 主に生成AIのコア技術である基盤モデルの開発に対する計算資源の提供や、データやAIの利活用に向けた実証調査の支援等を実施するプロジェクト。
-
*2リーズニング性能 … LLMが単に情報を検索したりテキストを生成したりするだけでなく、複数のステップからなる論理的な思考プロセスを経て結論を導き出す性能。
-
*3画像トークン … LMMはテキストや図表のデータをトークンと呼ばれる符号に変換してから処理します。画像トークンとはこのうち図表を符号に直したものを指します。
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が実施する、国内における生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)*1」において、マルチモーダル大規模言語モデル(以下「LMM」)の開発に取り組んできました。このたび、リコーは日本企業の図表を含むドキュメントの読み取りに対応したLMMの基本モデルの開発を完了したことをお知らせします。視覚とテキストの両方の情報を活用する日本語の質問応答データセットであるJDocQAおよび独自ベンチマークツール*2による検証の結果、他のモデルと比較しても優れた性能を示すことが確認されました(2025年4月24日時点)。リコーは、7月29日から開催される画像の認識・理解シンポジウム 「MIRU2025」にて論文を発表し、本基本モデルおよび独自に開発したベンチマークツールを無償で公開します。
今回の成果
リコーは、本基本モデルの開発に際して、文字/円グラフ/棒グラフ/フローチャートなどの視覚データ合計600万枚以上を人工生成しました。学習用データの人工生成手法を確立することで、大量の学習用データの整備が可能となり、LMMの性能向上に寄与しています。
開発パートナーの1社であるFastLabel株式会社(代表取締役CEO:鈴木 健史、以下「FastLabel」)からは、学習用および評価用の実データの収集とアノテーション*3業務の支援を受けました。FastLabelとは、リコーが主催するアクセラレータープログラム「TRIBUS(トライバス)2022」での採択がきっかけで、両社の協業が始まりました。
また、セキュリティやプライバシー、ガバナンスなどの観点から、オンプレミスや自社データセンターなどの社内専用環境でAIを利用したいと考える企業も多く、省リソースでのAI活用のニーズが高まっています。リコーが開発したLMMは、アーキテクチャも改良され、オンプレミス環境において、お客様情報を用いた追加学習が可能なコンパクトなモデルサイズを実現しています。具体的には、本モデルは、図表を処理するVision Encoder(ビジョンエンコーダー)*4という第1階層と、第1階層からの出力を後段のLLMが理解できる形式に変換するAdapter(アダプター)という第2階層、そして第2階層で変換された情報と文字情報を統合処理するLLMの第3階層の3層構造になっています。第1階層においては複数のVision Encoderを評価し、「Qwen2-VL-7B-Instruct*5」に採用されている手法を選定しました。また、第3階層においてもオンプレミス環境で実装可能な70Bクラスのモデルを複数評価し、「Llama-3.1-Swallow-70B-Instruct-v0.3*6」を選定しました。さらに、第2階層であるAdapterに独自の工夫*7を追加することにより、別々のモデルが由来であるため本来は接続できない第1・第3階層を、精度を維持しながら接続することに成功しました。
このように、アーキテクチャを改良する独自技術と大量の人工データによる学習を組み合わせることで、同規模のオープンソースモデルを凌ぐ性能を確保しながら、省コスト・省リソースでの運用を実現します。

評価手法としては、JDocQAに加えて、日本企業の文書に特有な複雑な図表をテストデータの中心に据えた、マルチモーダル性を評価する評価手法も独自に開発し、本モデルの性能を確認しました。
リコーは、本開発にあたり、アマゾン ウェブ サービス(以下、AWS)*8から、計算資源の提供及び技術サポートを受けています。「採択事業者が計算リソース提供事業者と個別に調整し直接確保」するスキームを通じて、NVIDIA H200 Tensor Core GPU を搭載するAmazon EC2 P5eインスタンスが提供されています。開発終盤での総合的な学習ならびに顧客向けファインチューニングにおいて、安定的で大規模な資源提供を迅速に受けることで、今回の成果につながっています。
リコーは、これまでのLLMの開発においても、「AWS LLM開発支援プログラム」と「AWS 生成AIイノベーションセンター(AWS Generative AI Innovation Center)」による支援のもと、効率的な開発を実現しています。
なお、今回の取り組みにおいて、基本モデルをチューニングして個社の業務に合わせて精度を向上させる手法も確立しました。具体的には、損害保険ジャパン株式会社(代表取締役社長:石川 耕治、以下「損保ジャパン」)が保有する保険の引受規定が記載された図表などを含むマニュアルを用い、同社の保険業務に対応するように学習(ファインチューニング)を行ったプライベートなモデルは、基本モデルに比べて顕著に性能が向上しました。今後、同社がトライアル運用する保険業務に関する規定、マニュアル、Q&Aデータなどを学習させ、社内外からの照会内容に対して最適な回答案を自動生成するシステム「おしそんLLM*9」に適用を検討していく予定です。
今後の予定
リコーは、基本モデルと独自に開発したマルチモーダル性能を評価する環境を無償で公開します。リコーは、GENIACで得られた成果を広く社会に還元することで、日本企業の知の結晶ともいえるドキュメントの利活用を促進し、業務革新と効率的で付加価値の高い働き方を支援することで、日本企業の企業価値の向上に貢献することを目指して取り組みを進めてまいります。
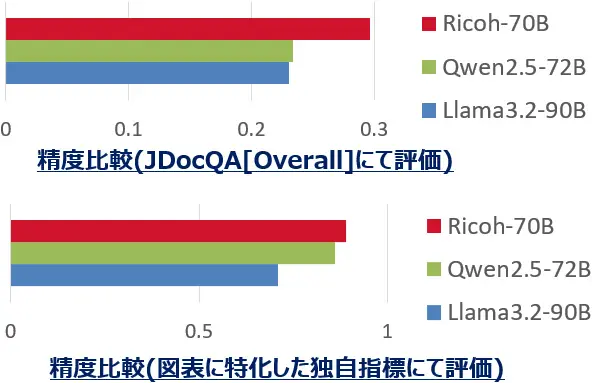
ベンチマークツールにおける他モデルとの比較結果
(上段は一般的な指標、下段はリコーが独自開発した指標による評価)
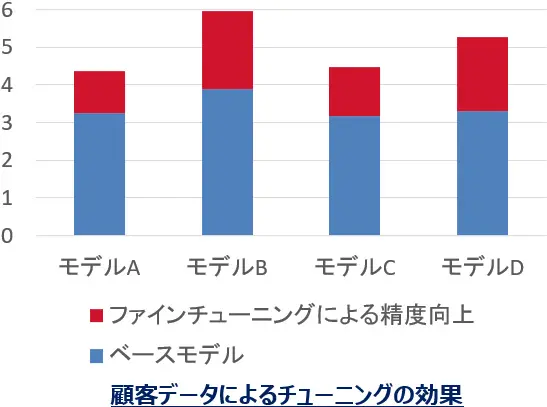
チューニングの成果
(モデルが異なっていてもファインチューニングによりグラフの赤い部分の精度向上が見られる)
-
*1GENIAC(Generative AI Accelerator Challenge):リコーは、NEDOが、2024年7月に実施した公募「ポスト5G情報通信システムの開発/競争力ある生成AI基盤モデルの開発(助成)」(以下、「本事業」)に採択されました。本事業では、主に生成AIのコア技術である基盤モデルの開発に対する計算資源の提供や、データやAIの利活用に向けた実証調査の支援等が行われます。
-
*2ベンチマークツールについて:図表を含む日本語文書をもとにして,視覚情報とテキスト情報の両方を参照する質問応答データセット JDocQAとリコーで独自開発したデータセットの2種類のベンチマークツールを活用して評価しました。
 https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/C3-5.pdf
https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/C3-5.pdf -
*3アノテーション(annotation):データにタグを付与して整理し、AIが正しく認識できるように加工するプロセス。AIが正しく学習できるよう、データに「正解」や「特徴」などを注釈のように書き込むことで、AIがデータから何を学習すべきかを明確にします。
-
*4Vision Encoder(ビジョンエンコーダー):図表などの視覚情報を言語モデルが理解できる形に変換するモジュール。
-
*5Qwen2-VL-7B-Instruct:https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
-
*6Llama-3.1-Swallow-70B-Instruct-v0.3:https://huggingface.co/tokyotech-llm/Llama-3.1-Swallow-70B-Instruct-v0.3
-
*7佐藤諒,木下彰,中田乙一,金箱裕介,麻場直喜. 大規模マルチモーダルモデルにおけるビジョンエンコーダーの付け替えと、日本語に強いモデル作成へ向けて. 言語処理学会 第31回年次大会 発表論文集. pp.954-959,2025.
-
*8
-
*9おしそんLLMについて:損保ジャパンのニュースリリース「大規模言語モデルを活用した照会回答業務の効率化トライアルの実施」https://www.sompo-japan.co.jp/-/media/SJNK/files/news/2024/20241022_1.pdf
ニュースリリース
リコーテクニカルレポート
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、経済産業省が推進する国内の生成AIの開発力強化を目的としたプロジェクト「GENIAC(Generative AI Accelerator Challenge)」のもと、国立研究開発法人新エネルギー・産業技術総合開発機構(以下、NEDO)が2024年8月に実施した公募「ポスト5G情報通信システムの開発(委託、助成)/計算可能領域拡大のための計算基盤技術開発(委託、助成)/競争力ある生成AI基盤モデルの開発(助成)」(以下、本事業)に採択されました。本事業では、主に生成AIのコア技術である基盤モデルの開発に対する計算資源の提供や、データやAIの利活用に向けた実証調査の支援等が行われます。リコーは、本事業において、企業の知の結晶である様々な企業内ドキュメント群を読み取るマルチモーダルLLMの本格的な開発を開始します。
本事業における取り組み内容
日本企業の業務DXを促進するマルチモーダルLLMの開発。
- マニュアル等の様々な図表を読解可能なマルチモーダル性能。
- 製造現場で使われる長文のマニュアルや指示書を理解するためのロングコンテキスト処理能力。
- 企業特有のドキュメント群に容易に適用可能なカスタマイズ性能。
関連リンク
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、米Meta Platforms社が提供する「Meta-Llama-3-70B」の日本語性能を向上させた「Llama-3-Swallow-70B*1」をベースモデルに、同社のInstructモデルからベクトル抽出したChat Vector*2とリコー製のChat Vector*3をリコー独自のノウハウでマージすることで、高性能な日本語大規模言語モデル(LLM*4)を新たに開発しました。これにより、リコーが開発・提供するLLMのラインナップに、米OpenAIが開発したGPT-4と同等レベルの高性能モデルが追加されました。
評価結果*6(ELYZA-tasks-100)
複雑な指示・タスクを含む代表的な日本語のベンチマーク「ELYZA-tasks-100」において、今回リコーがモデルマージの手法で開発したLLMはGPT-4と同等レベルの高いスコアを示しました。また、比較した他のLLMはタスクによって英語で回答するケースが見られましたが、全てのタスクに対して日本語で回答して高い安定性を示しました。
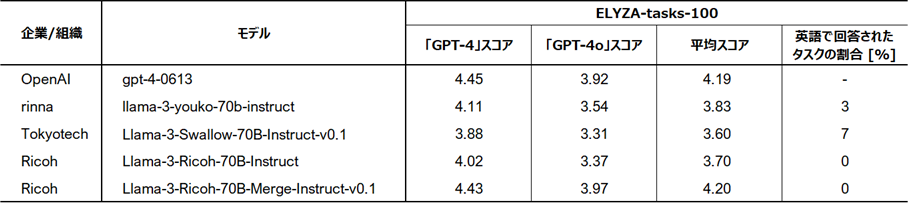
ベンチマークツール(ELYZA-tasks-100)における他モデルとの比較結果(リコーは最下段)
-
*1Llama-3-Swallow-70B:東京工業大学情報理工学院 情報工学系の岡崎直観教授と横田理央教授らの研究チームと国立研究開発法人 産業技術総合研究所によって開発された日本語LLMモデル。
-
*2Chat Vector:指示追従能力を持つモデルからベースモデルのウェイトを差し引き、指示追従能力のみを抽出したベクトル。
-
*3リコー製のChat Vector:Meta社のベースモデル「Meta-Llama-3-70B」に対し、リコー独自開発を含む約1万6千件のインストラクションチューニングデータで追加学習したInstructモデルから抽出したChat Vector。
-
*4Large Language Model(大規模言語モデル):人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*5モデルマージ:複数の学習済みのLLMモデルを組み合わせて、より性能の高いモデルを作る新たな方法のこと。GPUのような大規模な計算リソースが不要で、より手軽にモデル開発ができるとして、近年注目されています。
-
*62024年9月24日時点の評価結果。「スコア」の算出に際して、生成文の評価には「GPT-4」(gpt-4-0613)と「GPT-4o」(gpt-4o-2024-05-13)を使用し、英語での回答による減点は行っていない。「英語で回答されたタスクの割合」は100タスクのうち英語で回答されたものの割合。
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、お客様の業務効率化や課題解決での活用を目的に、企業ごとのカスタマイズを容易に行える700億パラメータの大規模言語モデル*1(LLM)を開発*2しました。製造業で特に重視される日本語・英語・中国語に対応したほか、お客様のニーズに合わせてオンプレミス・クラウドのどちらの環境でも導入可能です。入力された文章を単語などの細かい単位に分割するトークナイザーの独自改良により、高速処理と省コストを実現し、環境負荷低減にも貢献します。ベンチマークツールを用いた検証*3の結果、優れた性能を確認しました(2024年8月9日時点)。
リコーが開発した700億パラメータLLMの特徴
①高い日本語性能を持ち、英語・中国語にも対応可能
リコーのLLMは、AIが自然言語の学習に利用するコーパスの選定や、誤記や重複の修正などのデータクレンジング、学習するデータの順序や割合を最適化するカリキュラム学習などリコー独自の方法で学習されています。これにより日本語による安定した回答を実現しました。また、AWS(Amazon Web Services)と共同で開発した学習スクリプトに基づいて訓練されており、日本語、英語、中国語の多様な表現を学習済みです。
さらに、独自開発を含む約1万6千件のインストラクションチューニングデータで追加学習することにより、広範なタスクに適応する能力を獲得しました。これによりお客様のご要望に合わせてプライベートLLMを構築する際の追加学習で生じる破滅的忘却による性能低下を抑制し、高品質なプライベートLLMを開発することができます。
②トークナイザーの独自改良により、日本語の処理効率が同ベースモデルと比較して43%向上
リコーは、テキストをトークン*4に分割しLLMが理解できる形に変換するトークナイザーを独自に改良することで処理効率を向上させました。これにより、リソース削減、レスポンス時間の短縮、省コストを実現しました。LLMは処理に多くの電力が消費され環境負荷が大きいという社会課題に直面するなか、本技術は省エネルギー・環境負荷低減にもつながります。
③セキュリティを確保したオンプレミス環境で、学習~推論までご提供可能
通常、700億パラメータのLLMの運用や学習には、複数のサーバをネットワークで繋ぐ大規模なクラスタシステムが必要となります。リコーのLLMは独自の語彙置換技術やその他の最新技術を活用することによりモデルサイズを保ったまま学習が可能です。セキュリティ面でデータを自社内で保有したいお客様向けには、お客様先のクローズドな環境下での機密情報含めた追加学習が可能です。
④従来手法の開発と比較し、およそ50%のコスト低減および最大25%の電力消費量の削減を実現
「AWS LLM開発支援プログラム」と「AWS 生成AIイノベーションセンター(AWS Generative AI Innovation Center)」によるサポート提供のもと、AWS Trainiumアクセラレーターを搭載したAmazon Elastic Compute Cloud Trn1インスタンスを利用することで、効率的な開発を実現しました。お客様向けカスタムLLMを開発する際にも、より安価・短納期でのご提供が可能です。また、学習に際してTrn1インスタンスを活用することで、同等のアクセラレーテッドコンピューティングEC2インスタンスよりもエネルギー効率を最大25%改善しました。
評価結果(ELYZA-tasks-100)
複雑な指示・タスクを含む代表的な日本語のベンチマーク「ELYZA-tasks-100」において、リコーのLLMは平均で4を超える高いスコアを示しました。また、比較した他のLLMはタスクによって英語で回答するケースが見られましたが、リコーのLLMは全てのタスクに対して日本語で回答して高い安定性を示しました。さらに、回答速度の面でも他のLLMを大きく上回り、トークナイザーの改良の効果を確認しました。
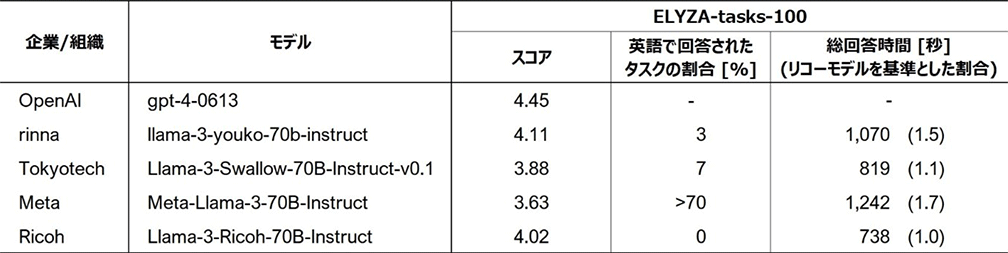
ベンチマークツール(ELYZA-tasks-100)における他モデルとの比較結果*3(リコーは最下段)
-
*1Large Language Model(大規模言語モデル)。人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*2このたびリコーが開発したLLMは、米Meta Platforms社が提供する「Meta-Llama-3-70B」の日本語性能を向上させた「Llama-3-Swallow-70B」をベースモデルに採用し、日本語と英語、中国語のオープンコーパス(自然言語の文章や使い方を大規模に収集し、一般公開されているデータセット)を追加学習させて開発したものです。
-
*32024年8月9日時点の評価結果。「Meta-Llama-3-70B」と公開されているその日本語継続事前学習モデルを比較対象として選定。参考として「GPT-4」の「スコア」も併記。「スコア」の算出に際して、生成文の評価には「GPT-4」(gpt-4-0613)を使用し、英語での回答による減点は行っていない。「総回答時間」はNVIDIA DGX H100においてGPUを2枚用いて計測。「英語で回答されたタスクの割合」は100タスクのうち英語で回答されたものの割合。但し、「Meta-Llama-3-70B-Instruct」は回答の大部分が英語または英語交じりの日本語だったため概算値。
-
*4LLMはテキストデータを「トークン」と呼ばれる単位で処理します。トークンとは、単語、文字セット、または単語と句読点の組み合わせです。
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、国立研究開発法人理化学研究所 革新知能統合研究センター 言語情報アクセス技術チーム(以下、理研 AIP)が主催する日本語インストラクションデータ作成プロジェクトに参画しています。リコーは、同チームとの共同開発で得られたインストラクションデータをリコー製130億パラメータの日本語LLM*1に追加学習させ、LLMの指示追従性能が向上するという結果を得ました。また、リコー独自開発のインストラクションデータ*2を追加学習させた結果においても、指示追従性能*3の向上を確認し、要約タスクでの優位性を確認しました。
今回、インストラクションデータ「ichikara-instruction」(10,329件)を用いてリコー製LLMにインストラクションチューニング*4を行いました。結果、複雑な指示・タスクを含む代表的なベンチマーク「ELYZA-tasks-100」において、チューニング前と比較し、指示追従性能の大幅なスコア向上が確認できました。また、リコーが独自開発した3,556件のインストラクションデータを用いたチューニング結果でも、同ベンチマークにおいて、同様にスコアが大きく向上しました。
これらの結果から、「ichikara-instruction」はインストラクションデータとして高品質なデータセットであること、また、リコー製インストラクションデータにおいても高スコアが得られたことから、LLMの性能向上にはデータ量だけでなく、データの品質が重要だということが示唆されました。(表1)
| モデル | スコア |
|---|---|
| リコー製130億パラメータLLM(インストラクションチューニングなし) | 1.19 |
| リコー製130億パラメータLLM+理研 AIPデータセット(10,329件) | 3.02 |
| リコー製130億パラメータLLM+リコー製データセット(3,556件) | 2.87 |
また、要約タスクを独自評価*5したところ、特に長文要約においては、リコー製データセットの優位性を確認できました。(表2)
AIによる要約生成はお客様のニーズが高く、リコーが強化していく領域です。リコーは継続的にデータ開発を進めており、2024年5月末時点では、5,000件超のインストラクションデータの開発を完了しています。今後、これらをリコーが提供するさまざまなAIソリューションに活用することで、より高品質なサービスの提供を目指します。
| モデル | ニュース要約 | 論文要約 |
|---|---|---|
| リコー製130億パラメータLLM+理研 AIPデータセット(10,329件) | 24.82 | 25.01 |
| リコー製130億パラメータLLM+リコー製データセット(3,556件) | 24.63 | 30.42 |
背景
労働人口減少や高齢化を背景に、生産性向上や付加価値の高い働き方の実現に向けて、多くの企業がAIの業務活用に注目しています。しかし、AIを実際の業務に適用するためには、その業種・業務の情報や、企業固有の用語や言い回しなどを含む大量のデータをLLMに追加学習させ、企業独自のAIモデル(プライベートLLM)を作成する必要があります。
リコー製LLMの特徴
リコーでは、お客様の想定用途に合わせてさまざまなデータ(企業独自の情報や知識を含む)を使ってドメイン適用された高精度なAIモデル(プライベートLLM)の個別開発を行っています。リコー製LLMは、日本企業の業務での活用を目的に開発され、企業ごとのカスタマイズを容易に行うことができることが特徴です。独自の学習上の工夫が組み込まれており、日本語としての文法や回答が正確で日本語精度が高く、日本企業が持つ情報資産の活用に適したモデルになっています。特にNLI(自然言語推論能力)において高性能という評価結果が出ています。2024年4月から、プライベートLLMをクラウド環境で提供開始しています。
今後、リコーはインストラクションデータの品質をさらに向上させ、インストラクションチューニング済みの高精度なプライベートLLMをご提供していくことで、お客様のAI活用を支援します。リコーは、お客様に寄り添い、業種業務に合わせて利用できるAIサービスの提供により、お客様が取り組むオフィス/現場のデジタルトランスフォーメーション(DX)を支援してまいります。
-
*1LLM:人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*2リコー独自開発のインストラクションデータ:2024年3月末時点で3,556件の開発を完了し、評価実施。その後、開発を継続し、24年5月末には5,091件のデータを開発。
-
*3指示追従性能:ユーザの指示や質問に対して自然な回答ができる能力。ユーザの意図を適切に理解し、それに応じた対応をできるかどうかを測る指標。
-
*4インストラクションチューニング:タスクに対して、指示(プロンプト)と正しい回答(インストラクションデータ)をセットで与えて受け答えを学習させる手法。
-
*5独自評価:評価データセットはリコーで独自に準備。ニュース要約:200件(要約対象の文字数:200~3000文字程度)。論文要約:100件(要約対象の文字数:2500~5500文字程度)。
関連情報
ニュースリリース
※掲載している情報は、発表当時のニュースリリースを原文のまま引用したものです。
リコーは、日本企業の業務での活用を目的に、企業ごとのカスタマイズを容易に行える130億パラメータの大規模言語モデル*1(LLM)を開発しました。日本語と英語での学習において、その学習データの比率を工夫することで、日本語としての文法や回答が正確で日本語精度の高い、日本企業が持つ情報資産の活用に適したモデルを実現しました。ベンチマークツールを用いた性能検証*2の結果、日本語で利用できる130億パラメータを持つ日本語LLMにおいて、2024年1月4日現在で最も優れた結果を確認しました。
労働人口減少や高齢化を背景に、AIを活用した生産性向上や付加価値の高い働き方が企業成長の課題となっており、その課題解決の手段として、多くの企業がAIの業務活用に注目しています。しかし、AIを実際の業務に適用するためには、企業固有の用語や言い回しなどを含む大量のテキストデータをLLMに学習させ、その企業独自のAIモデル(カスタムLLM)を作成する必要があります。このたびリコーが開発したLLMは、米Meta Platforms社が提供する「LLM Llama2-13B」をベースに、日本語と英語のオープンコーパス*3を追加学習させて開発したものです。①学習に利用するコーパスの選定 ②誤記や重複の修正などのデータクレンジング ③学習データの順序や割合を最適化するカリキュラム学習など、リコー独自の学習上の工夫が組み込まれていることが特徴です。学習の結果、特にNLI(自然言語推論能力)において高性能となっています。日本語LLMの性能評価で広く使われている日本語ベンチマークツール(llm-jp-eval)を用いた他LLMモデルとの性能比較*2では、評価スコアの平均値が最も高く、優れた性能を確認することができました。
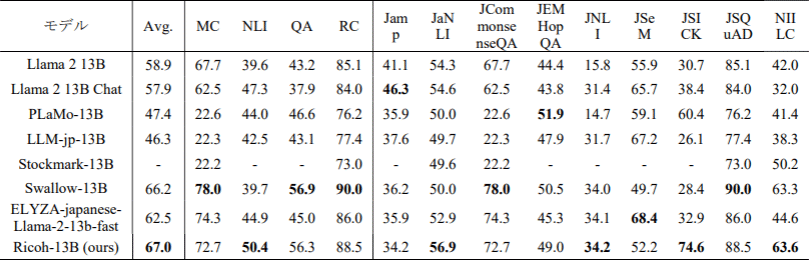
日本語ベンチマークツール(llm-jp-eval)における他モデルとの比較結果*2(リコーは最下段)
学習能力が高い本LLMに企業独自の情報や知識を取り入れることで、お客様ごとの業種・業務に合わせた高精度なAIモデル(カスタムLLM)を、短期間で容易に構築することが可能になります。カスタムLLMをお客様の業務で活用し、業務文書の要約や質問応答の作業をAIに置き換えることで、業務のワークフローを最適化し、業務効率化を実現します。
2024年春から、カスタムLLMをクラウド環境でお客様へ提供開始します。まずは日本国内のお客様より提供を開始し、今後海外のお客様への提供も目指します。
LLMは、パラメータ数が多いほどより多くの情報を処理でき、学習能力が高まる一方、より大きな計算リソースが必要になるうえ、学習や運用の難易度が上がり、開発難易度が高くなります。本モデルは「AWS™ LLM開発支援プログラム」によるサポート提供のもと、AWS Trainiumアクセラレーターを搭載したAmazon Elastic Compute Cloud Trn1インスタンスを利用することで、従来手法の開発と比較し45%のコスト低減および12%の開発期間短縮を実現することができました。さらに、お客様向けカスタムLLMを開発する際にも、効率的に開発することができるため、お客様へより安価・短納期でのご提供が可能です。
なお、今回のLLM開発とその手法は2024年3月11日から開催される言語処理学会*4第30回年次大会において論文発表する予定です。
リコーは、お客様に寄り添い、業種業務に合わせて利用できるAIサービスの提供により、お客様が取り組むオフィス/現場のデジタルトランスフォーメーション(DX)を支援してまいります。
-
*1人間が話したり書いたりする言葉(自然言語)に存在する曖昧性やゆらぎを、文章の中で離れた単語間の関係までを把握し「文脈」を考慮した処理を可能にしているのが特徴。「自然文の質問への回答」や「文書の要約」といった処理を人間並みの精度で実行でき、学習も容易にできる技術。
-
*22024年1月4日時点の評価結果。公開されている日本語LLMのうち130億パラメータかつトークナイザを日本語適応している事前学習モデルとの比較。
MC、NLI、QA、RC は、下記カテゴリー内の平均値。Avg.はその4カテゴリー平均値の平均値。
MC (Multi-Choice QA:多肢選択質問応答):jcommonsenseqa
NLI(Natural Language Inference:自然言語推論):jamp、janli、jnli、jsem、jsick
QA(Question Answering:質問応答):jemhopqa、niilc
RC(Reading Comprehension:読解):jsquad -
*3自然言語の文章や使い方を大規模に収集し、一般公開されているデータセット。
-
*4自然言語処理(NLP)分野では最大の学会です。学会発表するNLP2024は、言語処理学会の年次大会です。https://www.anlp.jp/
ニュースリリース



-
※GPT、GPT-4、GPT‑5およびGPT‑5‑nanoはOpenAI, L.L.C.の商標または登録商標です。
-
※Gemini、Gemini 2.5 Flash、Gemini 2.5 Pro、Gemini 3 Flash Preview、Gemini 3 Pro Preview、Gemini 3.1 Pro Preview、Gemini 3.5 Flash、Gemma、Gemma 3はGoogle LLCまたはその関連会社の商標または登録商標です。
-
※Llama、Llama 3.1、Llama 3.3はMeta Platforms, Inc.またはその関連会社の商標または登録商標です。
-
※Qwen、Qwen2-VL、Qwen3‑VL、Qwen3.5、Qwen3.6はAlibaba Group Holding Limitedまたはその関連会社の商標または登録商標です。
-
※その他、本ページに掲載の会社名、製品名は、各社の商標または登録商標です。